Regresión lineal
Clase 3
2 de abril de 2025
Clase factor
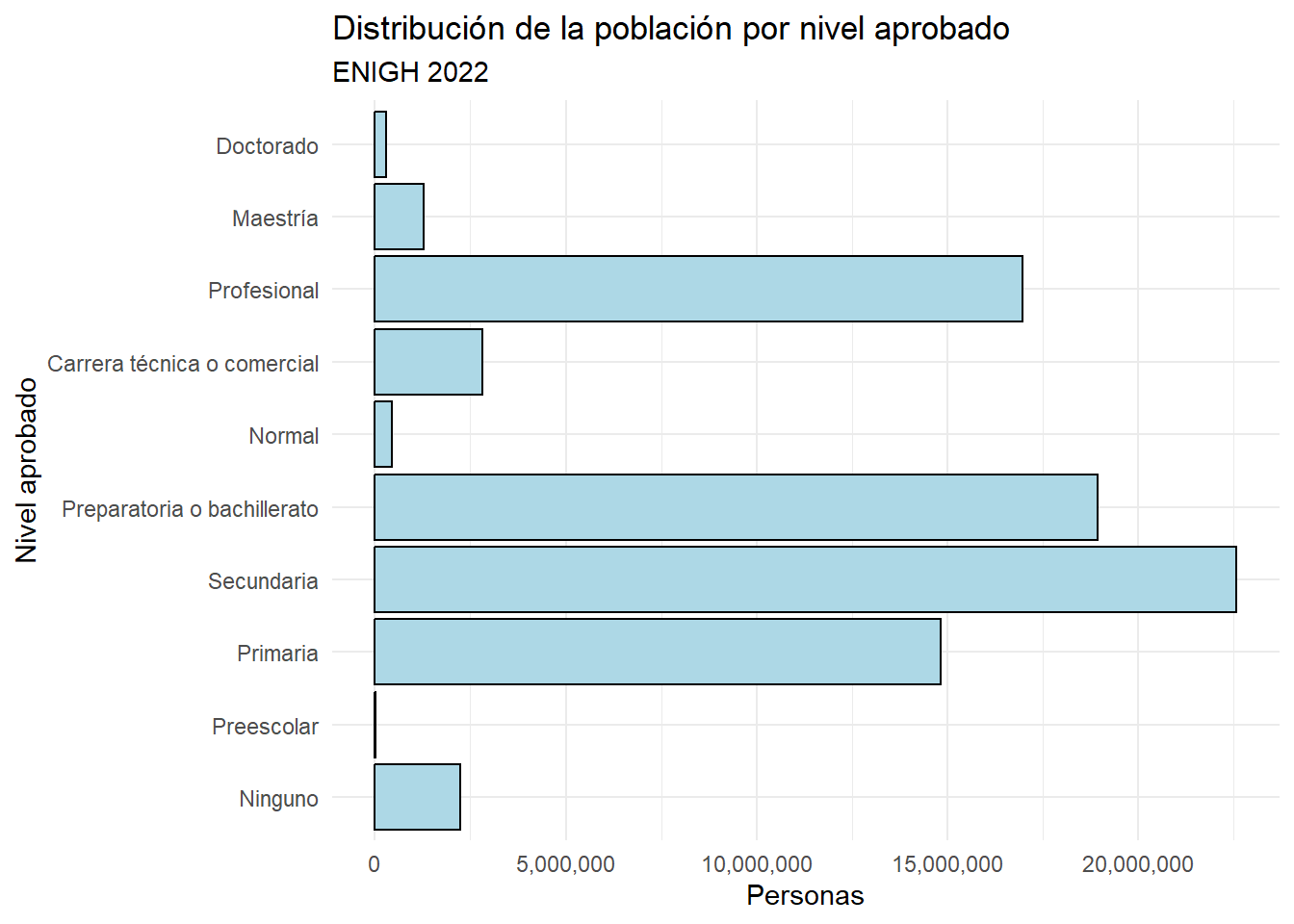
Notemos que la variable nivelaprob tiene clase factor.
Esta clase es útil para representar variables categóricas.
Asigna on orden a una serie de categorías, lo que facilita ordenar categorías por su nivel.
Por esto,
Ningunoes menor quePrimaria, que es menor queSecundaria, etc.Una librería del tidyverse que facilita el trabajo de variables categóricas es
forcats.
![]()
Distribución de nivel aprobado
Distribución del ingreso
Warning: The dot-dot notation (`..density..`) was deprecated in ggplot2 3.4.0.
ℹ Please use `after_stat(density)` instead.Warning: Removed 35855 rows containing non-finite outside the scale range
(`stat_bin()`).Warning: Removed 35855 rows containing non-finite outside the scale range
(`stat_density()`).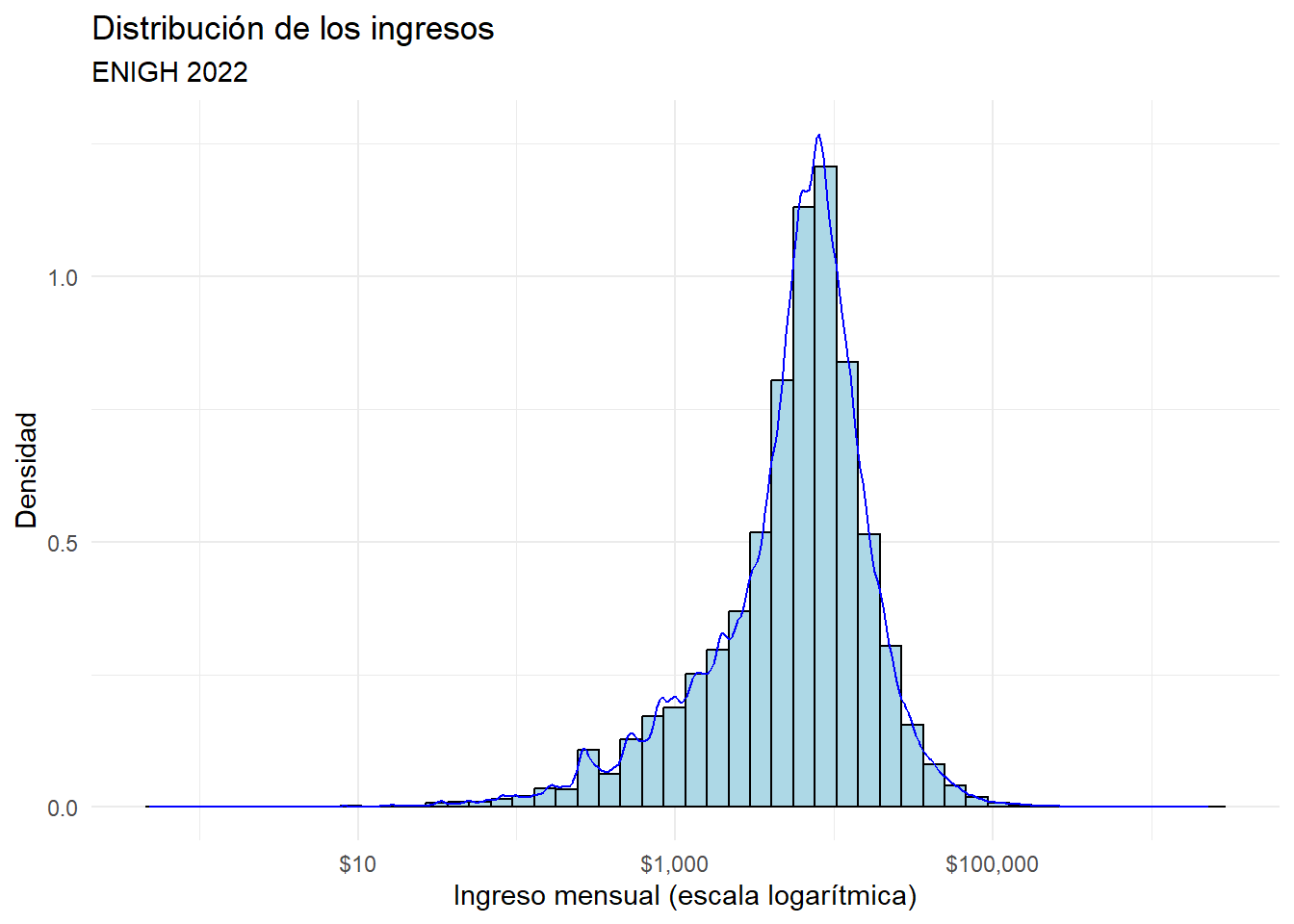
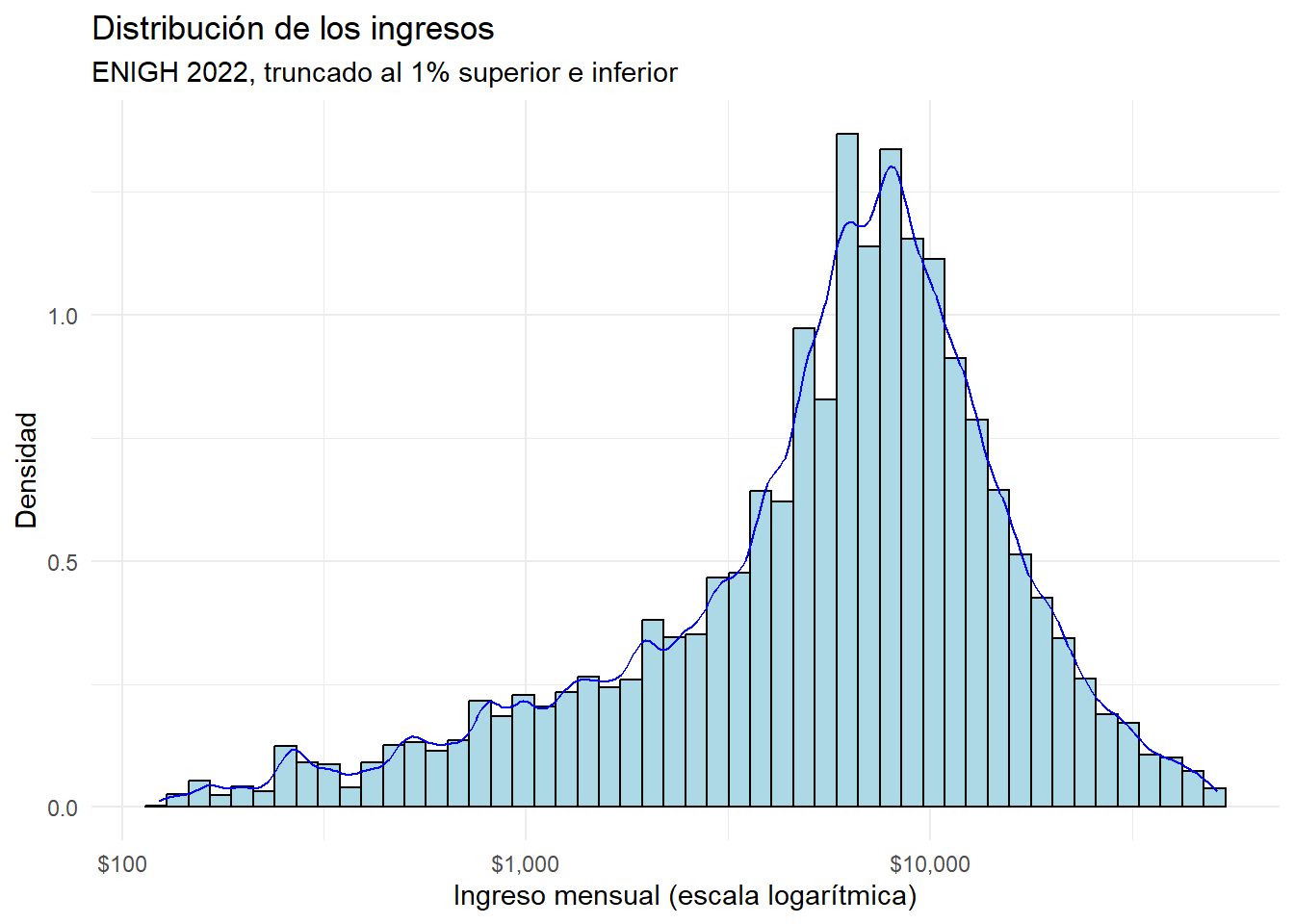
Distribución del ingreso después de truncar
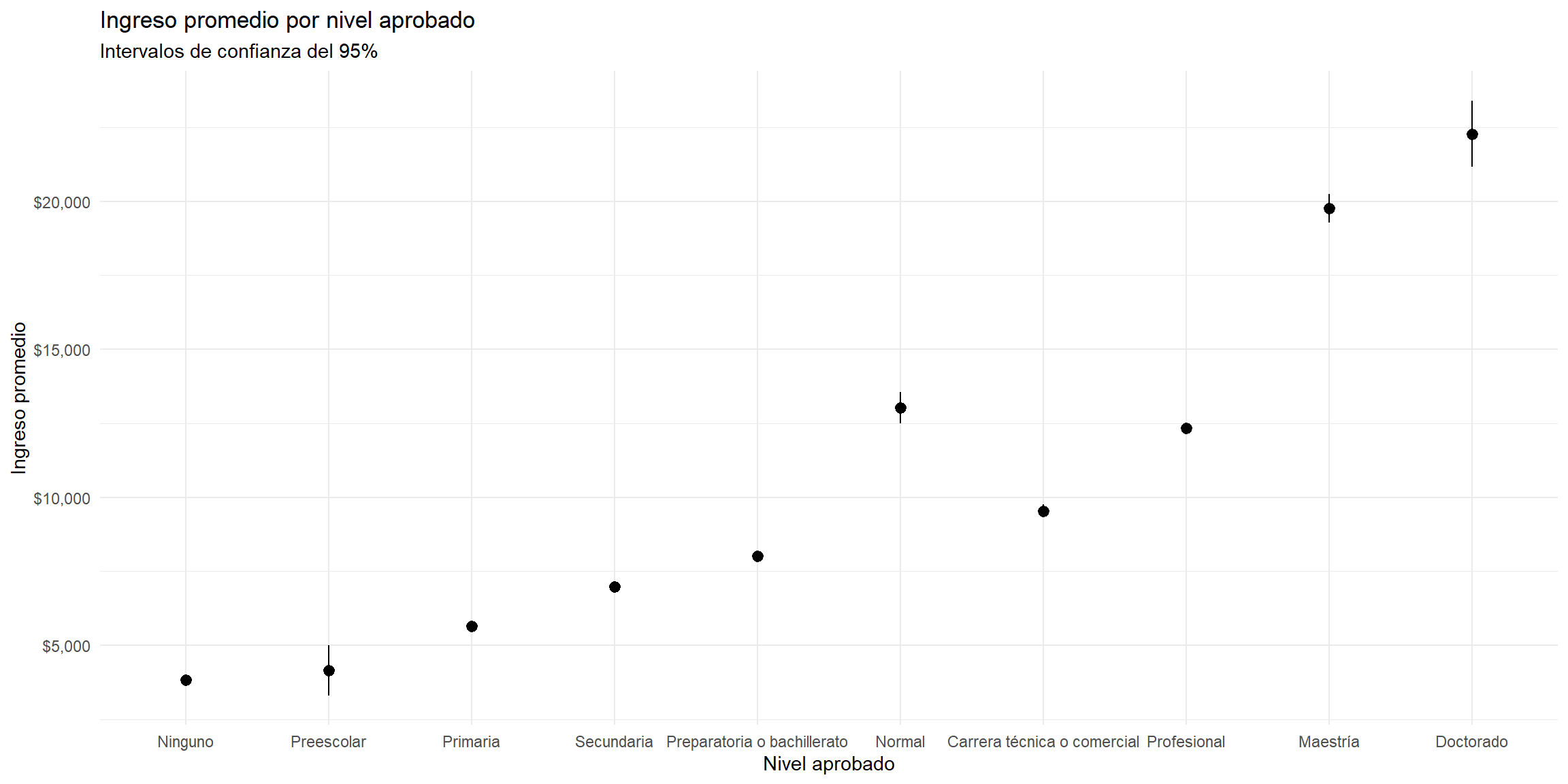
Ingreso promedio por nivel aprobado
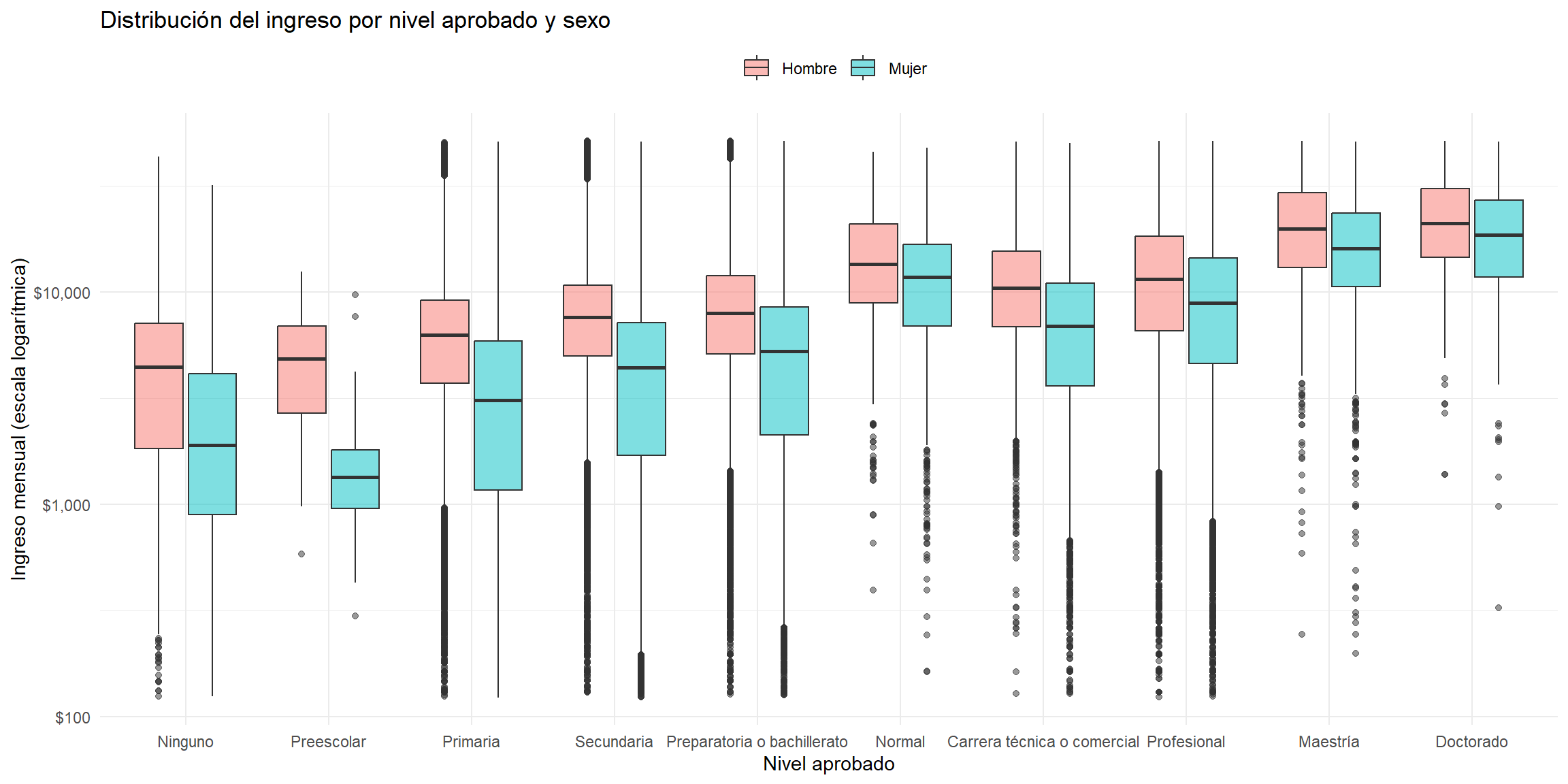
Distribución del ingreso por nivel aprobado y sexo
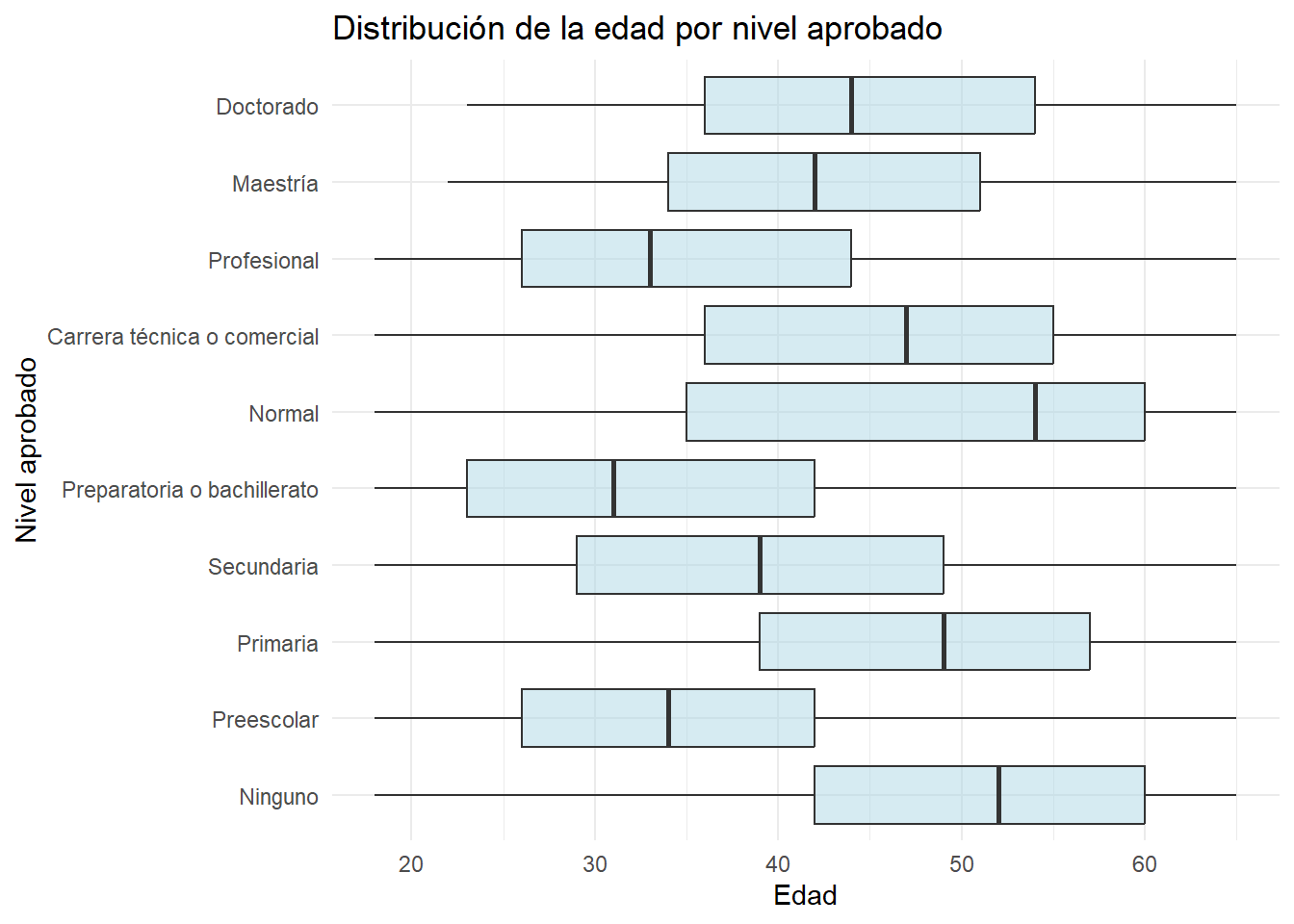
Escolaridad y edad
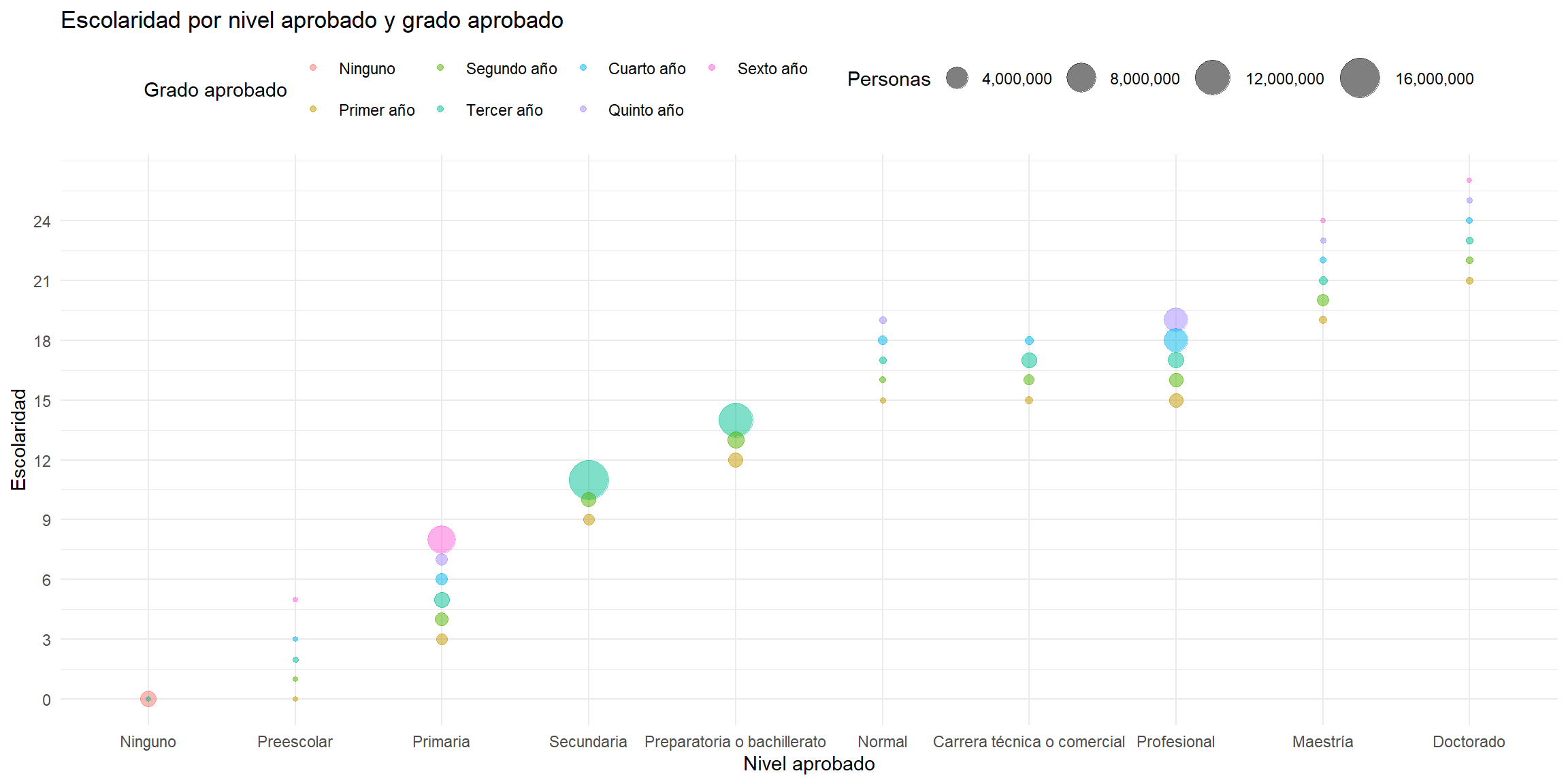
Imputación de años de escolaridad según el nivel aprobado
La ENIGH incluye el nivel y el grado de estudios aprobados, reportados por cada persona.
Pero no incluye los años de escolaridad.
Creé la variable escolaridad a partir de la variable nivelaprob y gradoaprob.
Relación no paramétrica entre escolaridad e ingreso
No summary function supplied, defaulting to `mean_se()`
`geom_smooth()` using method = 'gam' and formula = 'y ~ s(x, bs = "cs")'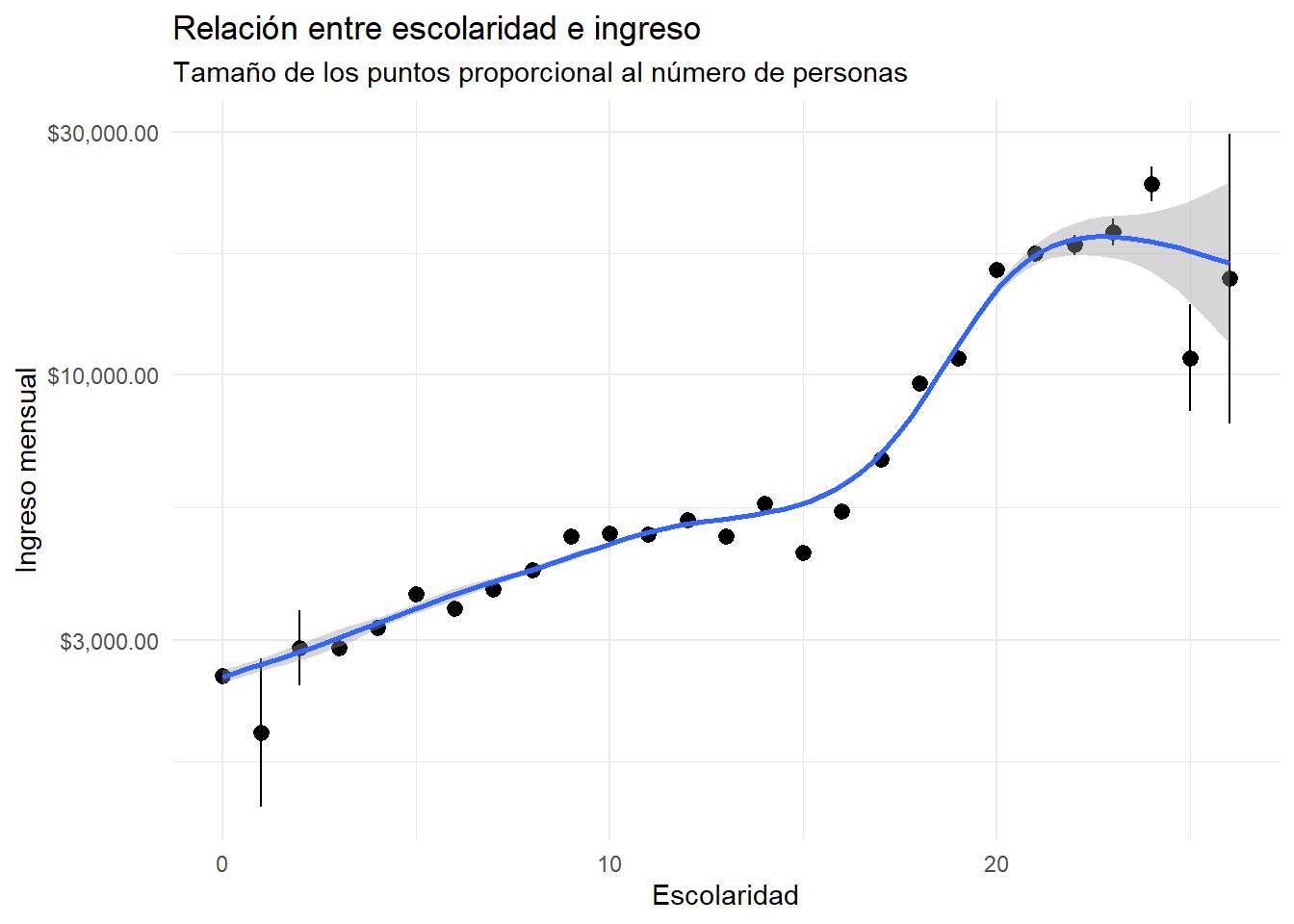
Simulación de un modelo de regresión lineal
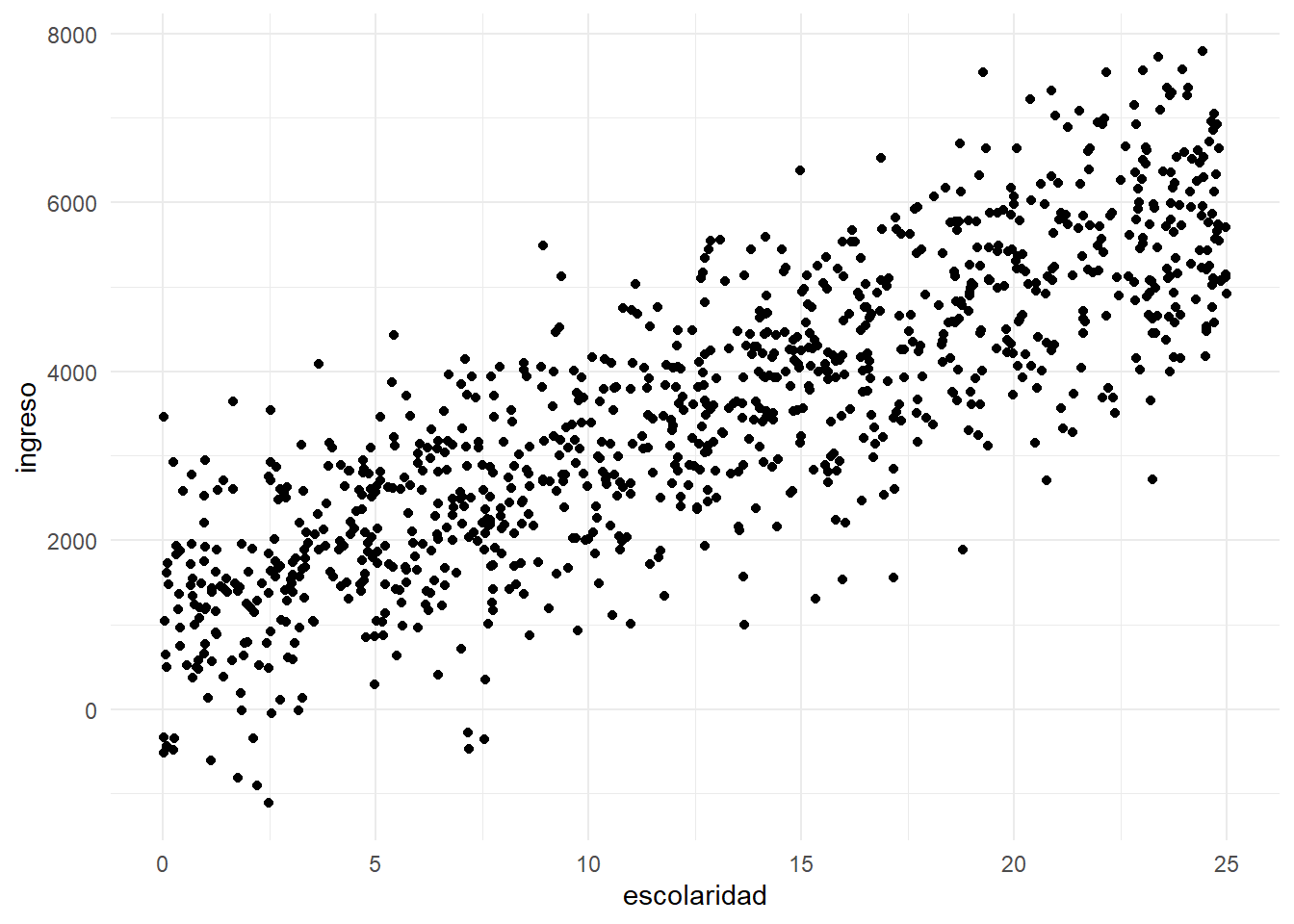
Estimación del modelo
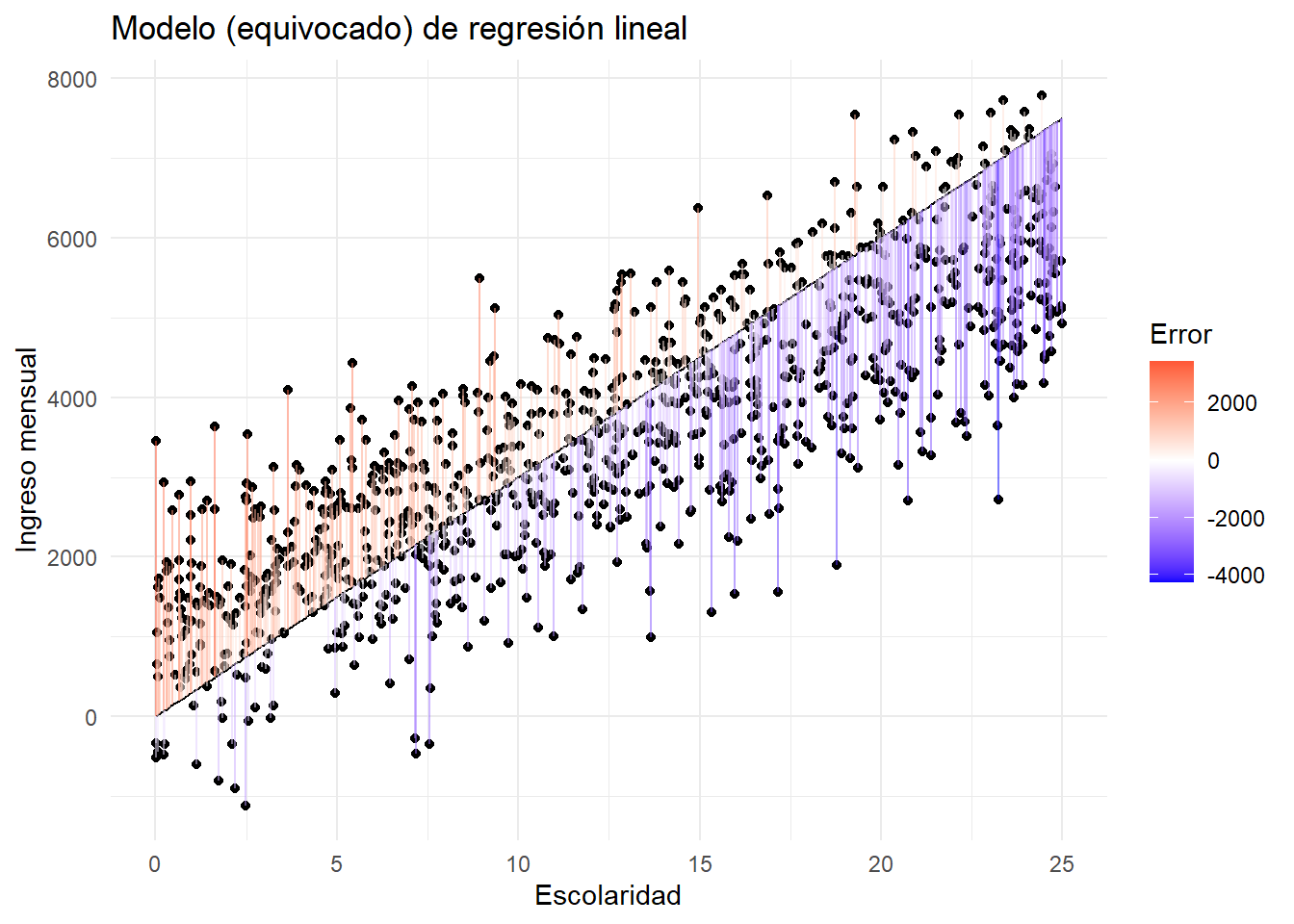
Visualización del modelo MCO
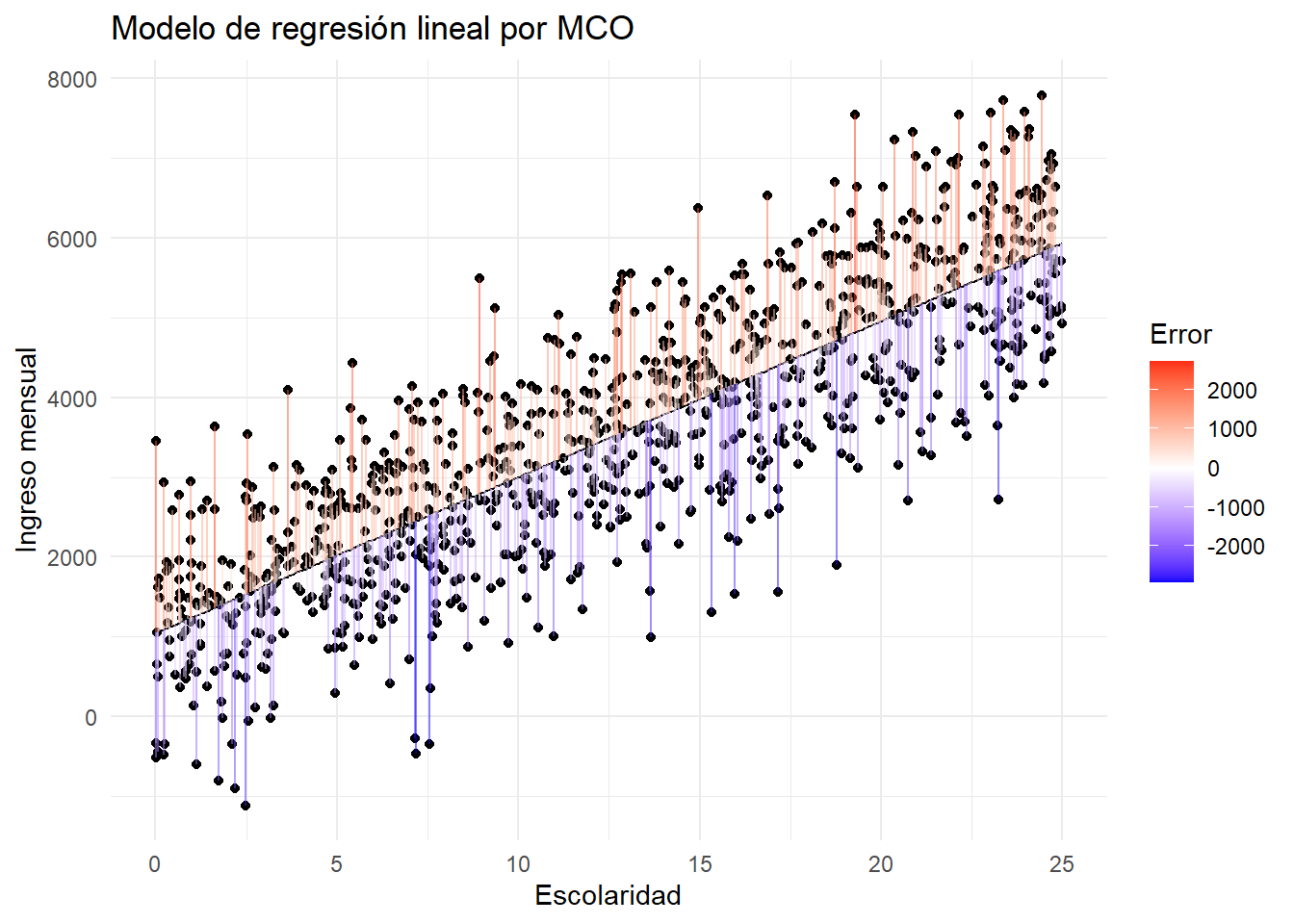
Comparación de los modelos
`geom_smooth()` using formula = 'y ~ x'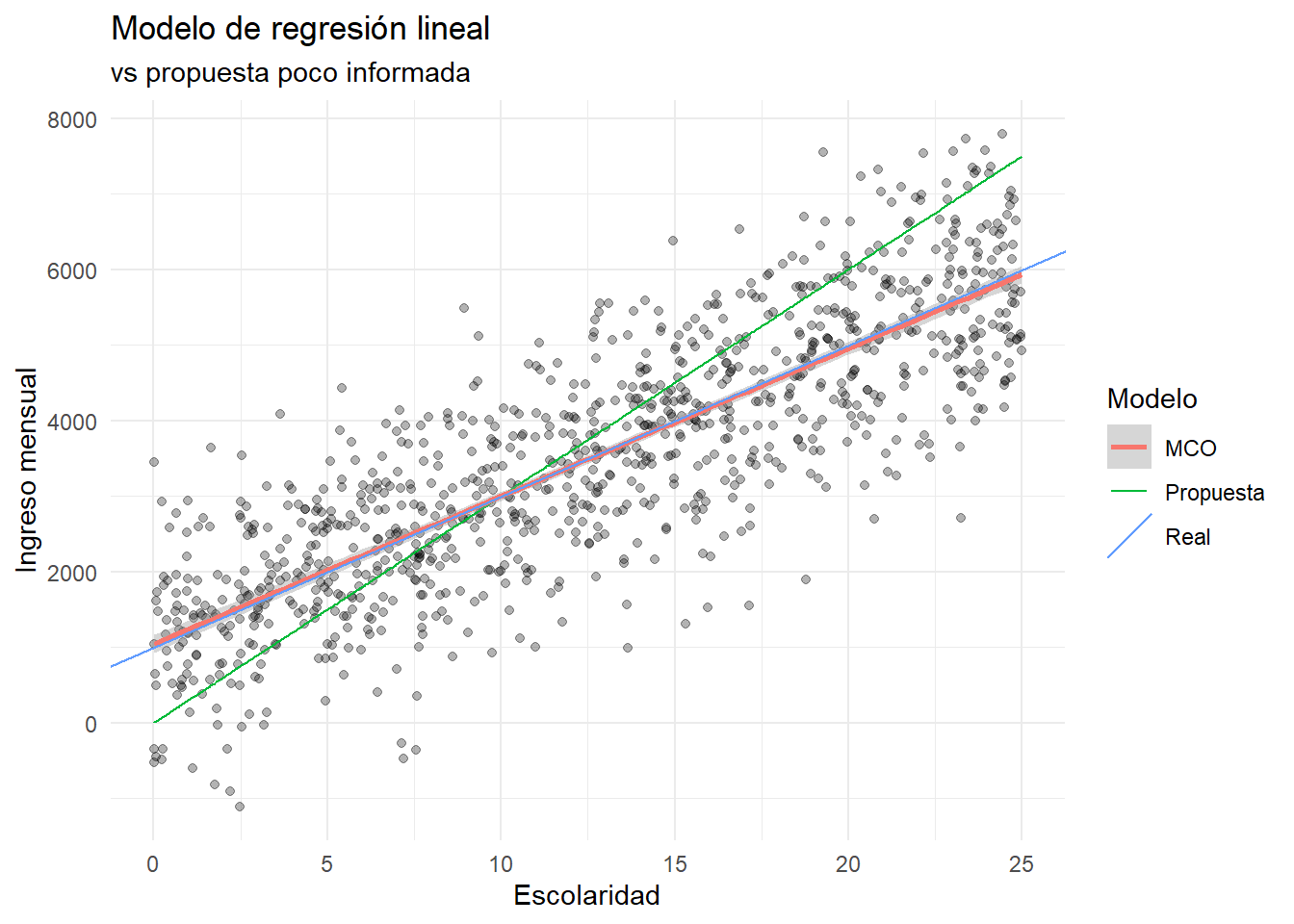
Rendimientos de la escolaridad
```{r}
#| results: asis
# Ojo para producir esta tabla en Quarto. Necesitamos:
# 1. Incluir la opción etable(..., markdown = T)
# 2. Usar `results: asis` en la opciones del chunk (ver arriba)
etable(
ingresos_fit,
poblacion_fit,
title = "Modelo de regresión lineal",
fitstat = ~ n + r2 + my + f,
markdown = T,
headers = list("Simulación" = 1, "ENIGH 2022ls " = 1)
)
```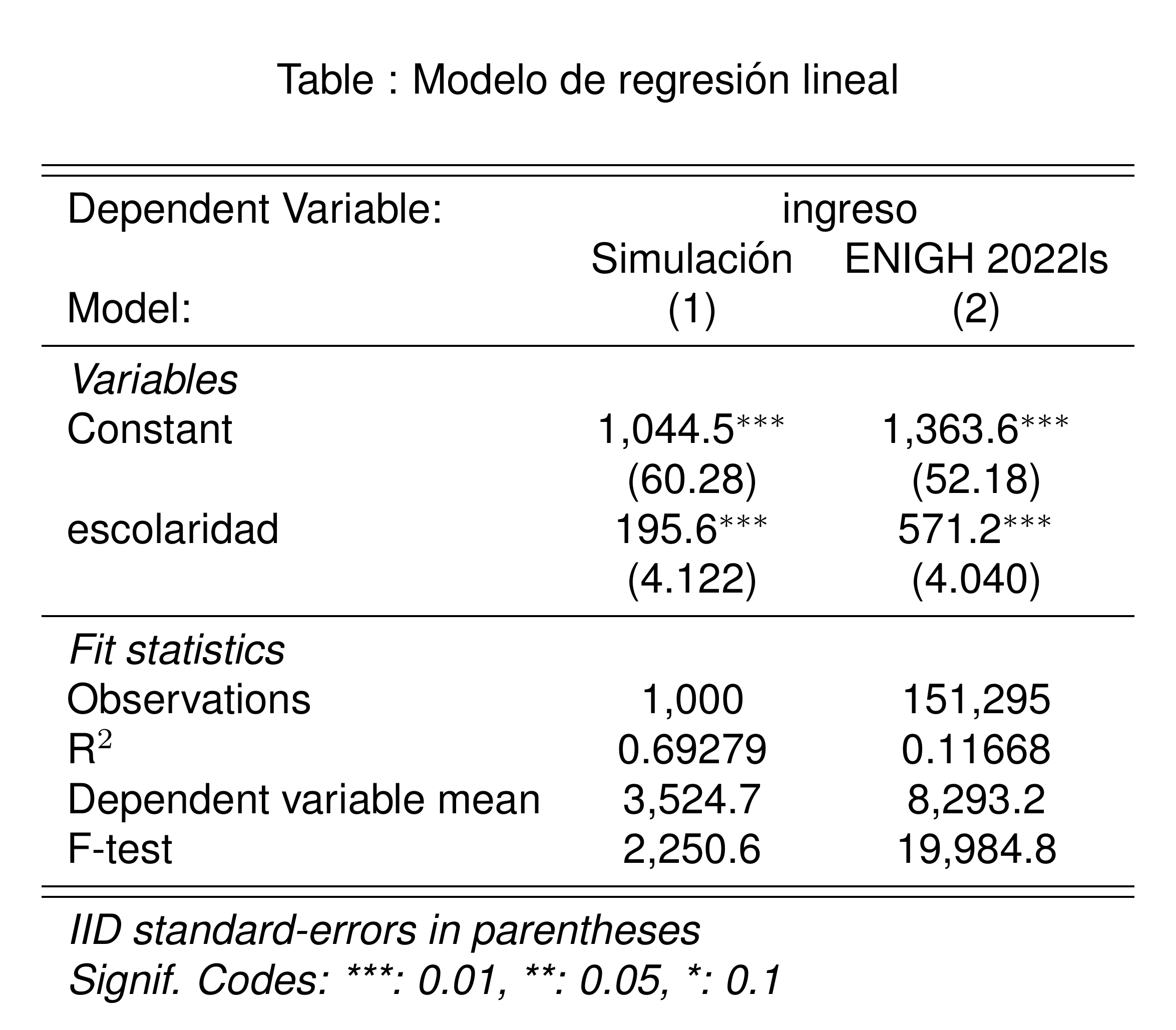
En promedio, un año adicional de escolaridad está relacionado con un ingreso adicional de $571 pesos al mes.
En promedio, una persona sin escolaridad tiene un ingreso mensual de $1,364.
\(R^2\) es una métrica de bondad de ajuste que mide la proporción de la varianza de la variable dependiente que es explicada por el modelo.
La escolaridad explica el 12% de la variación del ingreso en la población, mientras que el modelo simulado explica el 70% de la variación del ingreso.
Esto es esperado, porque definimos el modelo simulado de tal manera que la escolaridad es la única variable que afecta el ingreso.
Variabilidad en los estimadores
Estudiaremos la variabilidad de los estimadores de los coeficientes del modelo MCO en el mundo simulado que tenemos.
Imaginemos que tomamos métricas de escolaridad y de ingresos en una muestra aleatoria diferente, pero que comparte las características de la población simulada original.
ingresos_simulados_2 <- tibble(
id = 1:n,
escolaridad = runif(n, min = 0, max = 25),
ingreso = 1000 + (200 * escolaridad) + rnorm(n, mean = 0, sd = 1000)
)
ingresos_sim_fit <- feols(ingreso ~ escolaridad, data = ingresos_simulados)
ingresos_sim_fit_2 <- feols(ingreso ~ escolaridad, data = ingresos_simulados_2)
etable(
ingresos_sim_fit,
ingresos_sim_fit_2,
fitstat = ~ n + r2 + my + f,
markdown = T,
headers = list("Simulación 1" = 1, "Simulación 2" = 1)
) 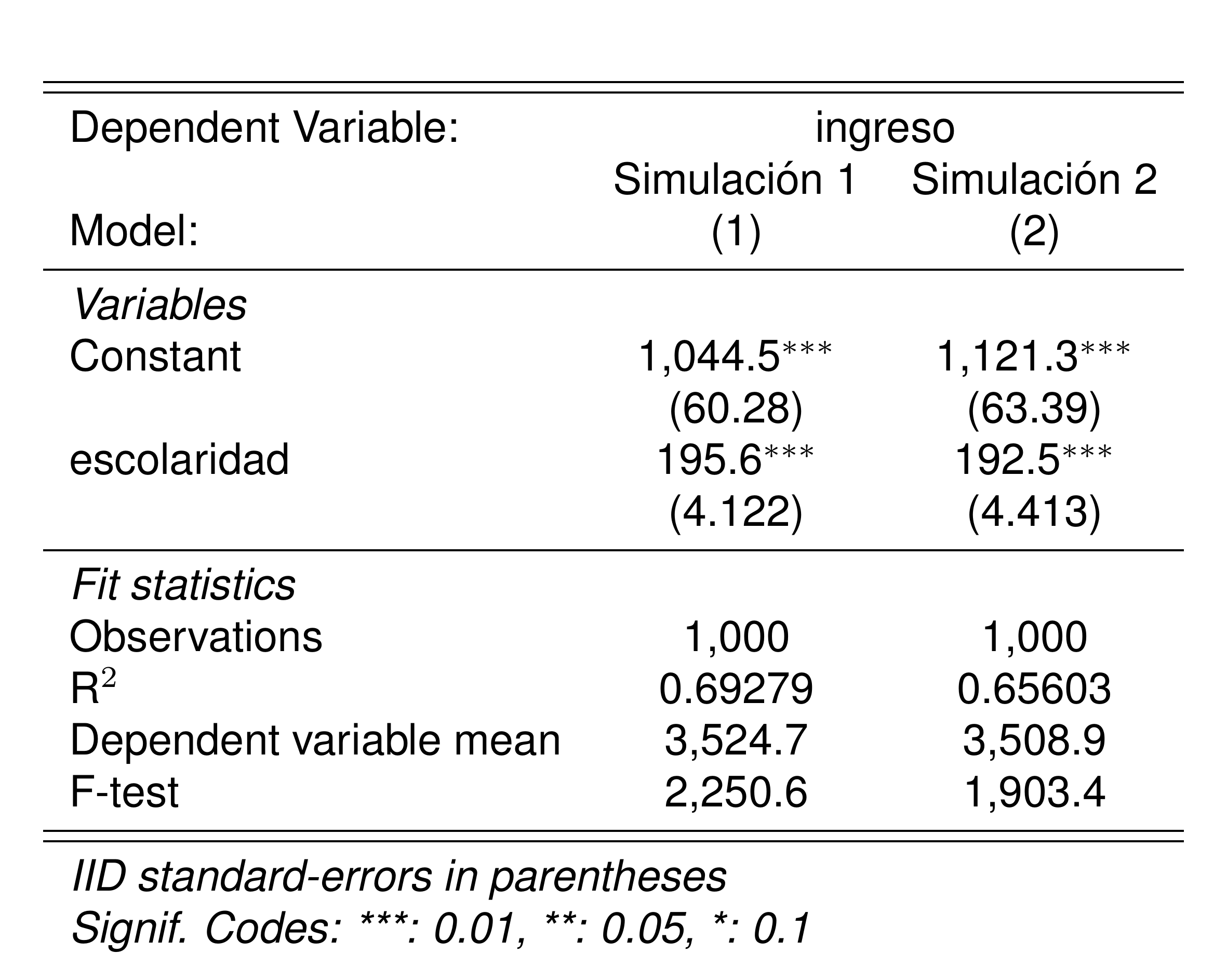
Encontramos que los coeficientes han variado al usar una muestra diferente.
Variabilidad en los estimadores
simulaciones_long <- simulaciones |>
pivot_longer(
cols = c(intercept, escolaridad),
names_to = "coef",
values_to = "valor"
)
simulaciones_long |>
ggplot(aes(x = valor)) +
geom_histogram(
aes(y = ..density..),
bins = 50,
fill = "lightblue",
color = "black"
) +
geom_density(
aes(y = ..density..),
color = "blue"
) +
# Add means
geom_vline(
data = simulaciones_long |>
summarise(
.by = coef,
mean = mean(valor)
),
aes(xintercept = mean),
color = "red",
linetype = "dashed"
) +
facet_wrap(~ coef, scales = "free") +
labs(
x = "Valor del coeficiente",
y = "Densidad",
title = "Distribución de los coeficientes MCO",
subtitle = "10,000 simulaciones, n = 1,000"
)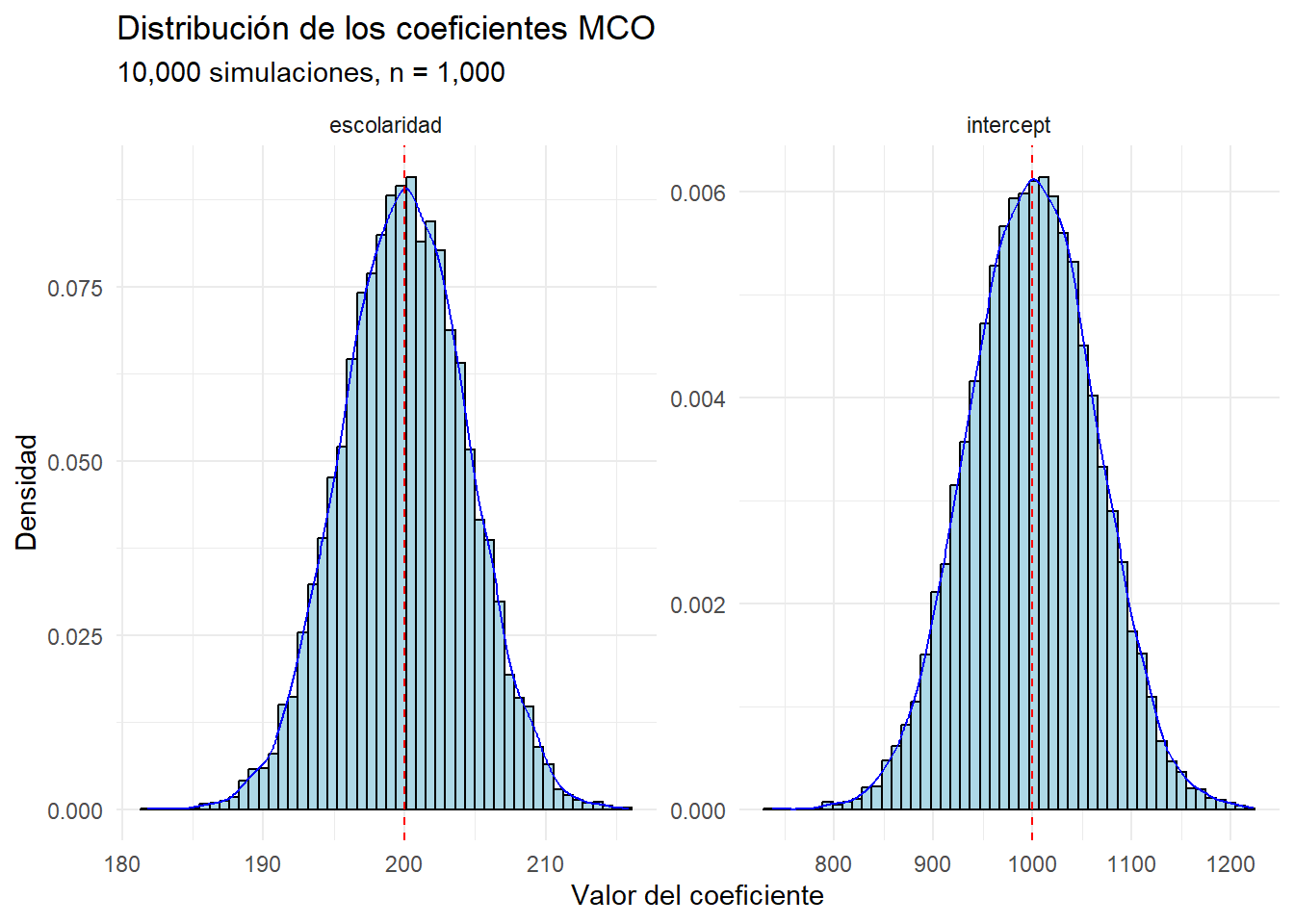
Los coeficientes de MCO siguen una distribución normal.
- Esto sigue de que su interpretación es promedio.
¡La media de los coeficientes estimados es igual al verdadero valor de los coeficientes!
Esto es una propiedad de los estimadores de MCO: son insesgados.
Esto significa que, en promedio, el estimador de MCO es igual al verdadero valor del parámetro.
La inferencia de los coeficientes sigue de la misma manera que una prueba de hipótesis de un promedio.
Inferencia para coeficientes
Regresemos a la tabla de coeficientes, donde podremos encontrar algunas pruebas de hipótesis ya calculadas.
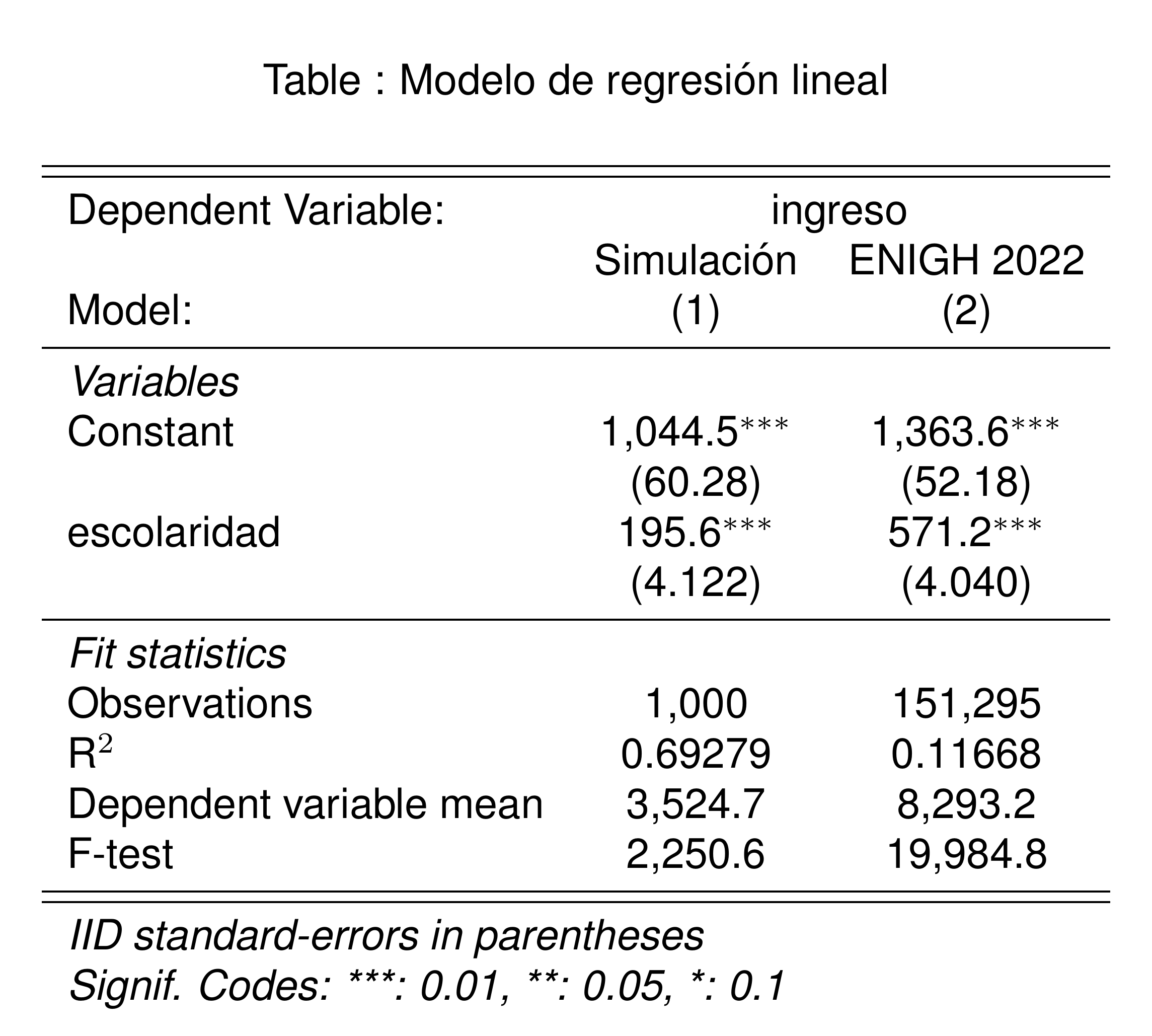
El error estándar de los coeficientes es una medida de la variabilidad de los estimadores, en la misma escala que los coeficientes.
Si multiplicamos el error estándar por 1.96, obtenemos un intervalo de confianza del 95% para el coeficiente.
Si el intervalo de confianza no incluye 0, podemos rechazar la hipótesis nula de que el coeficiente es igual a 0.
Las estrellas indican para qué niveles de significancia podemos rechazar la hipótesis nula de que el coeficiente es igual a 0.
Adicionalmente, la prueba F es una prueba conjunta de la relevancia del modelo completo. Un valor mayor a 100 indica que el modelo es relevante.
Nuestros dos modelos, el simulado y el de la ENIGH, tienen un coeficiente de escolaridad significativo al 1% y son modelos relevantes.
Educación e ingresos
Queremos estimar el efecto de la escolaridad en los ingresos.
Sin embargo, puede haber una variable habilidad que determina tanto la escolaridad como el ingreso.
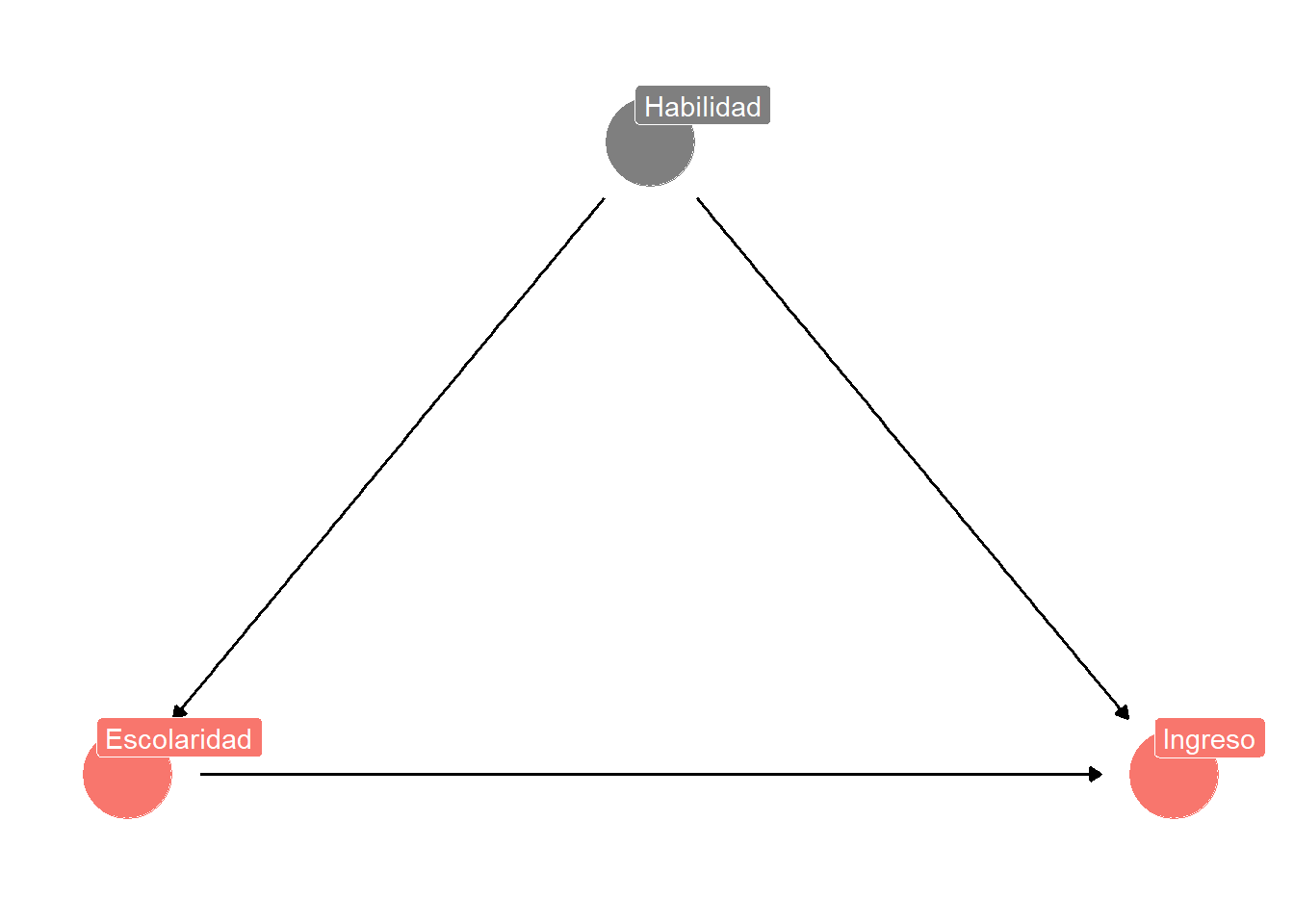
¿Cómo afectaría la omisión de la variable habilidad a la estimación del modelo de regresión lineal?
Sesgo por variable omitida
En la ENIGH no tenemos información sobre la variable habilidad…
¡Pero podemos simularla!
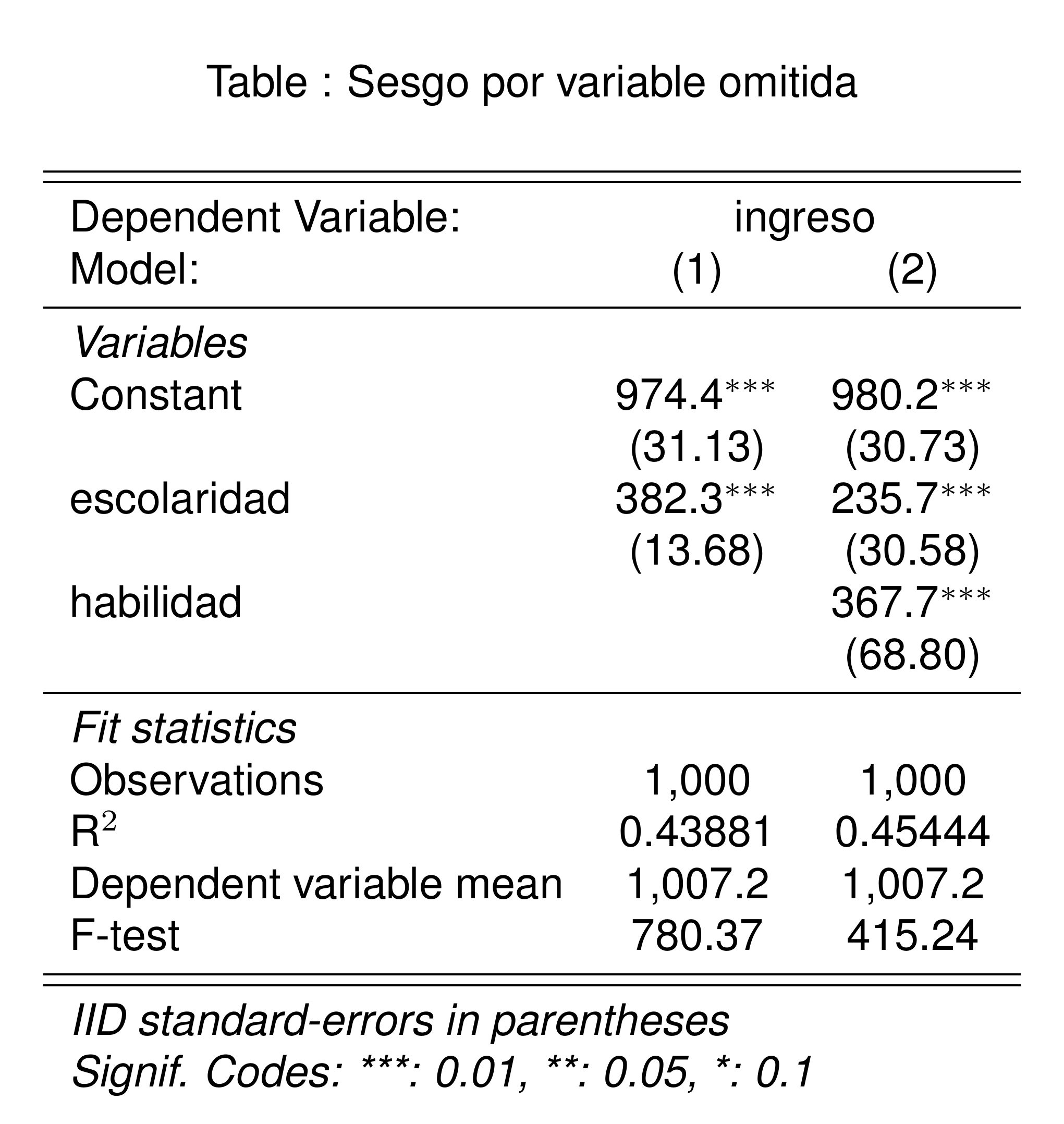
El modelo que omitió la variable
habilidadsobreestimó el efecto de la escolaridad en el ingreso.Esto siempre pasará cuando exista una variable omitida que esté correlacionada con la variable dependiente y con la variable independiente.
El modelo MCO solo será insesgado cuando no haya variables omitidas.
Correlación entre ingreso, escolaridad, edad y sexo
Revisemos empíricamente si sexo y edad están correlacionadas con ingreso y escolaridad.
- Necesitamos un modelo por cada par de variables:
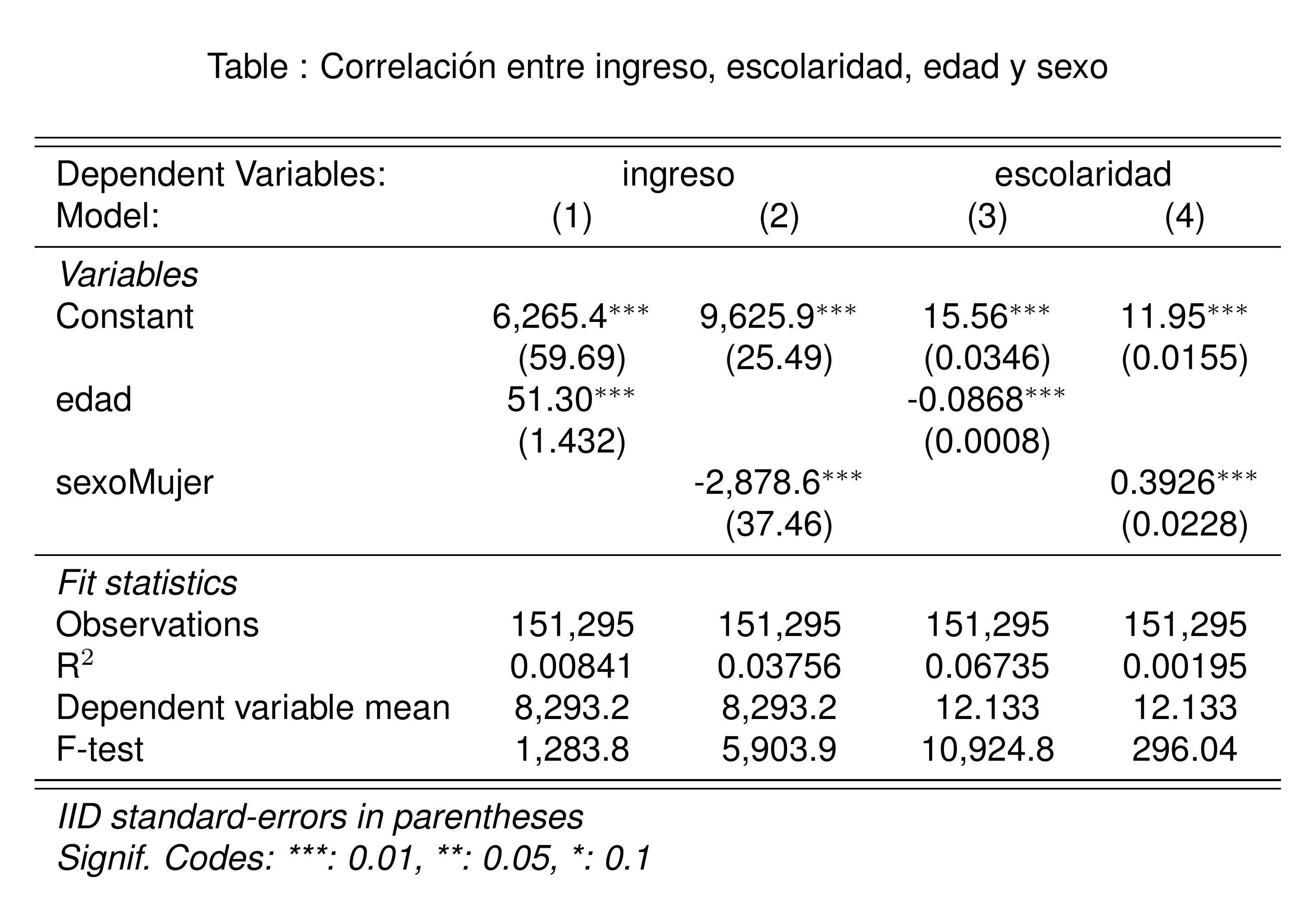
Para saber si existe correlación, podemos ir a la prueba F, que indica la relevancia del modelo completo.
Las pruebas F de todas las regresiónes son más grandes que 100, lo que indica que todos los modelos son relevantes y que
sexoyedadestán correlacionadas coningresoyescolaridad.
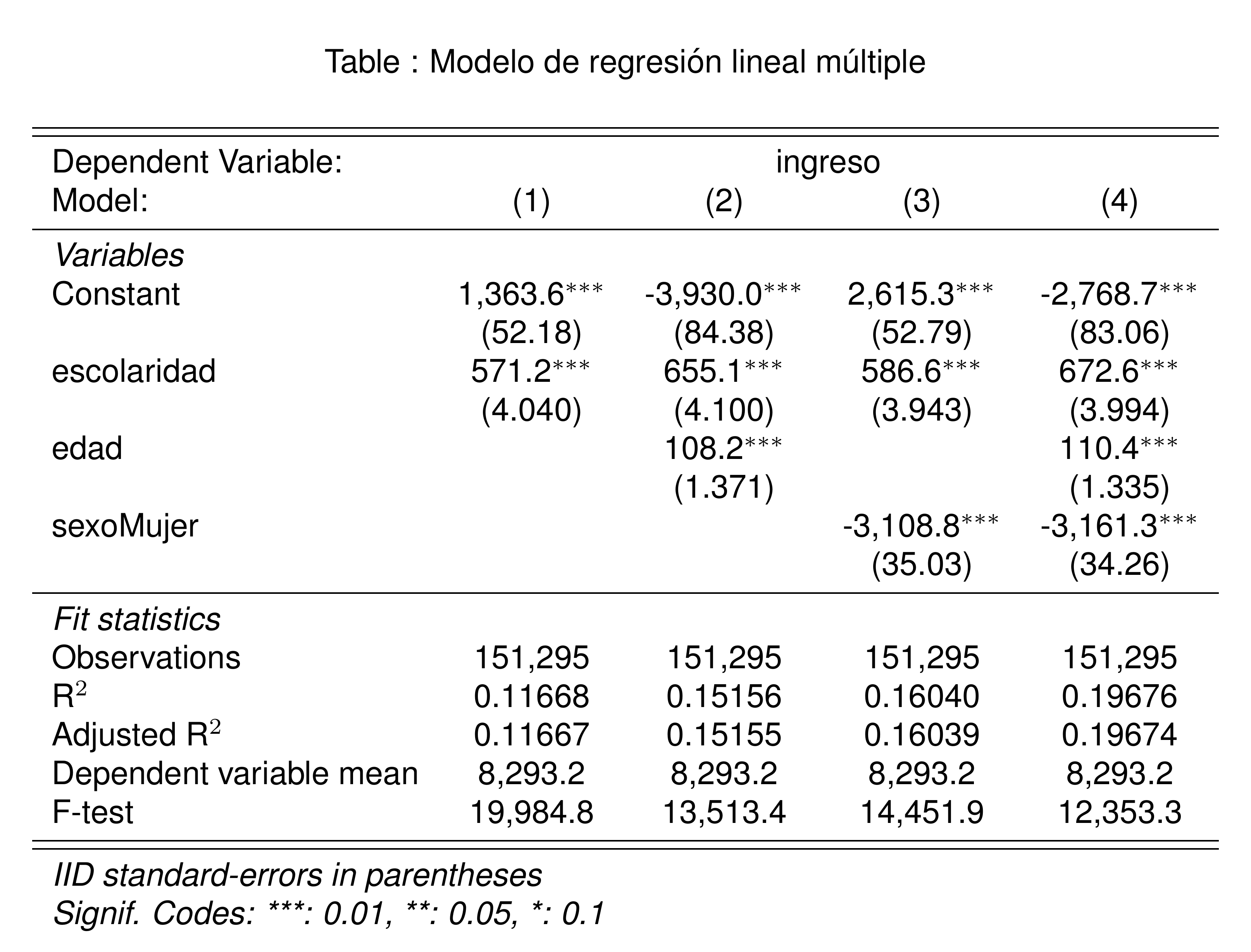
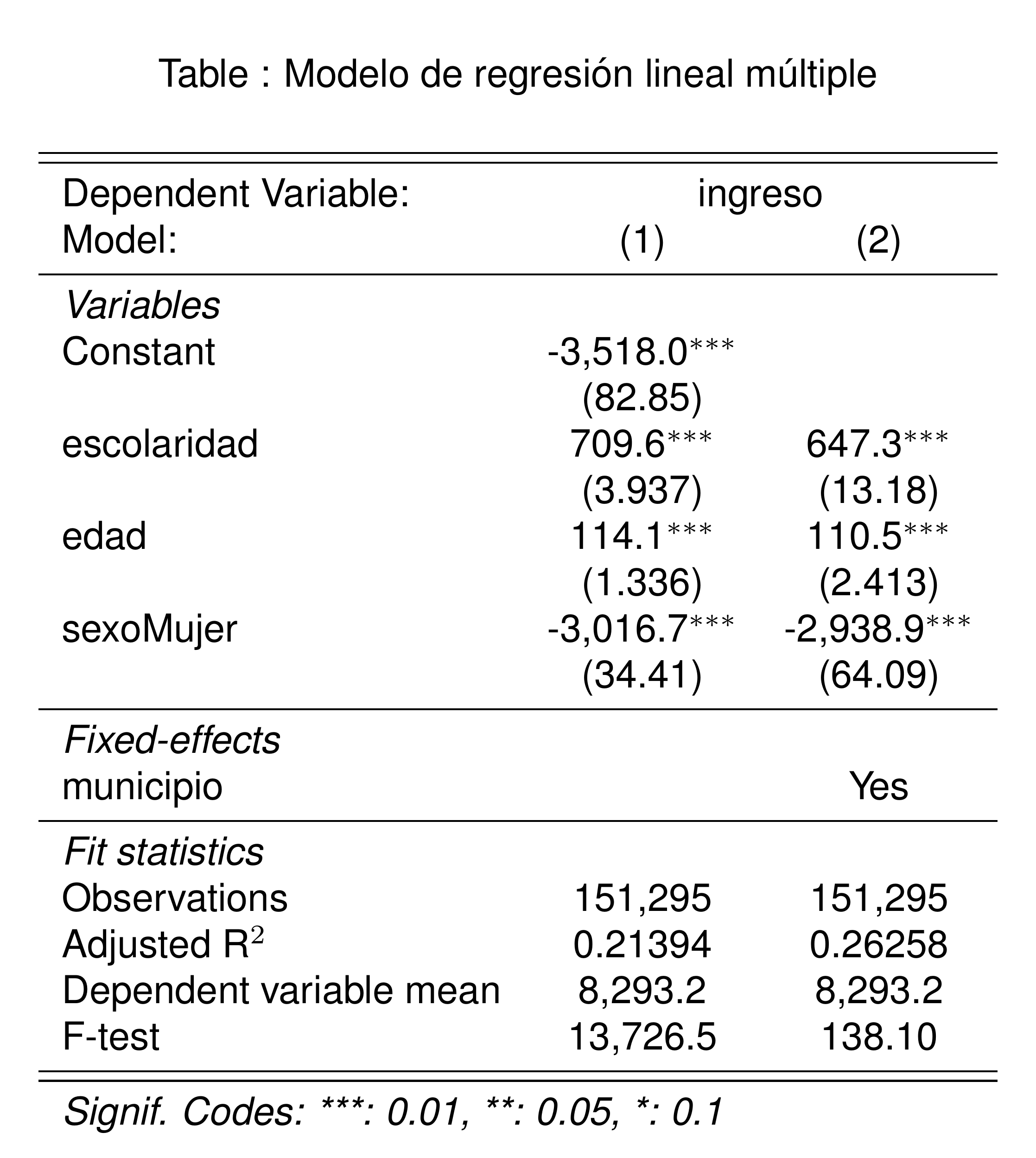
Implementación del modelo
Veamos cómo afecta la estimación del rendimiento de la escolaridad al incluir edad y sexo en el modelo, una por una:
simple_fit <- feols(ingreso ~ escolaridad, data = poblacion)
multiple_fit_1 <- feols(ingreso ~ escolaridad + edad, data = poblacion)
multiple_fit_2 <- feols(ingreso ~ escolaridad + sexo, data = poblacion)
multiple_fit_3 <- feols(ingreso ~ escolaridad + edad + sexo, data = poblacion)
etable(
simple_fit,
multiple_fit_1,
multiple_fit_2,
multiple_fit_3,
title = "Modelo de regresión lineal múltiple",
fitstat = ~ n + r2 + ar2 + my + f,
markdown = T
) 
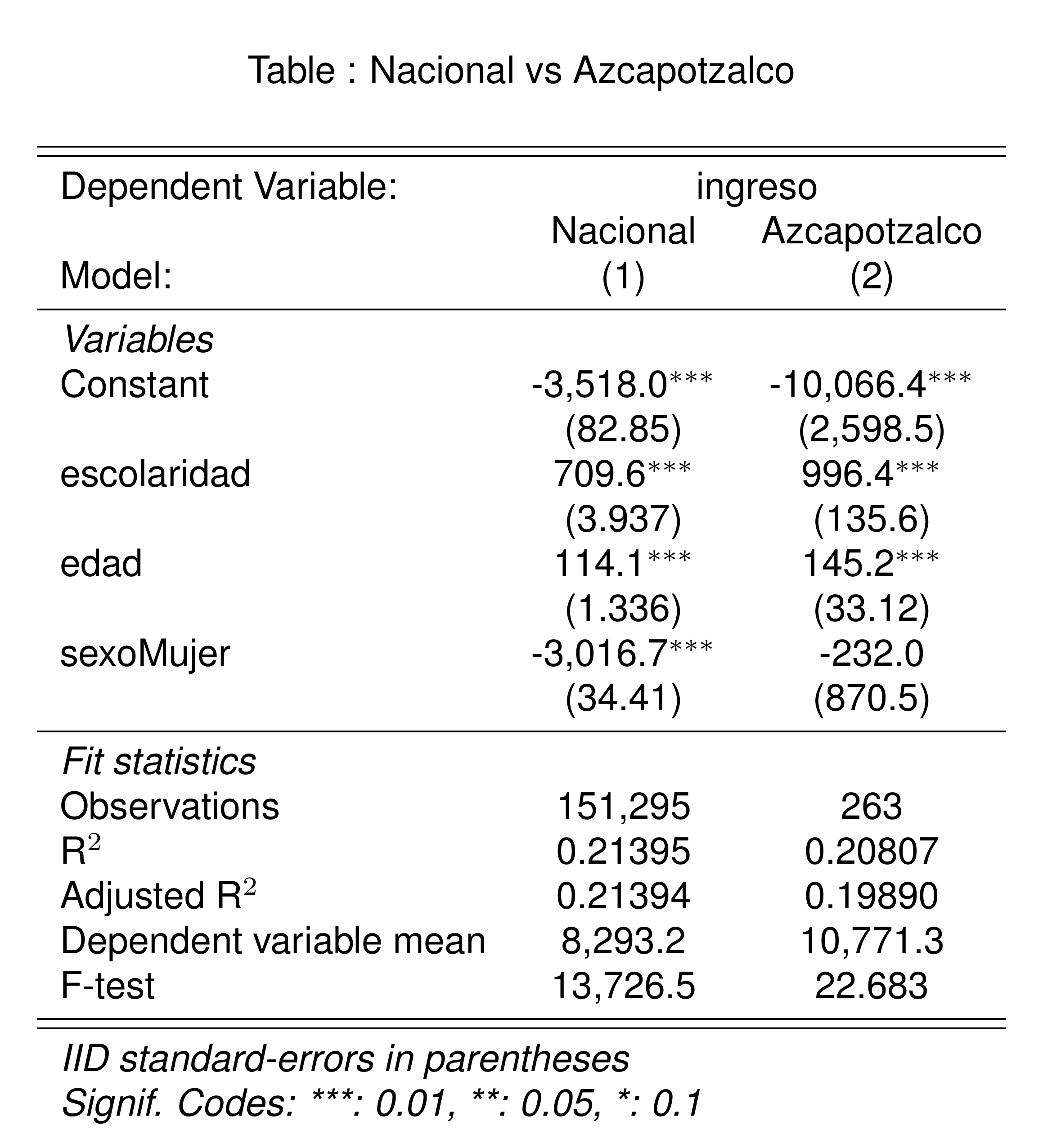
Comparación al interior de un municipio
Podríamos empezar a atender esta crítica comparando el ingreso de las personas al interior de un municipio en particular.
Por ejemplo, en Azcapotzalco, CDMX.
Algo que todavía no discutimos es que la ENIGH es una encuesta, por lo que, para tener un estimador representativo, tenemos que ponderar por el factor de expanción usando el argumento
weightsde la funciónfeols().
azcapotzalco <- poblacion |>
filter(cve_ent == "09", cve_mun == "002") # Azcapotzalco, CDMX
pob_fit <- poblacion |>
feols(ingreso ~ escolaridad + edad + sexo, weights = ~factor)
azc_fit <- azcapotzalco |>
feols(ingreso ~ escolaridad + edad + sexo, weights = ~factor)
etable(
pob_fit,
azc_fit,
title = "Nacional vs Azcapotzalco",
fitstat = ~ n + r2 + ar2 + my + f,
markdown = T,
headers = list("Nacional" = 1, "Azcapotzalco" = 1)
)
Estimación
fixest es el paquete perfecto para estimar modelos de efectos fijos.
- Simplemente agregamos la variable
municipiodespués de un|al final de la fórmula del modelo.
Estimación
Estimación
Transformación polinomial
Recordemos de la sección de estadística descriptiva que estimamos el ingreso promedio por escolaridad.
No summary function supplied, defaulting to `mean_se()`
`geom_smooth()` using method = 'gam' and formula = 'y ~ s(x, bs = "cs")'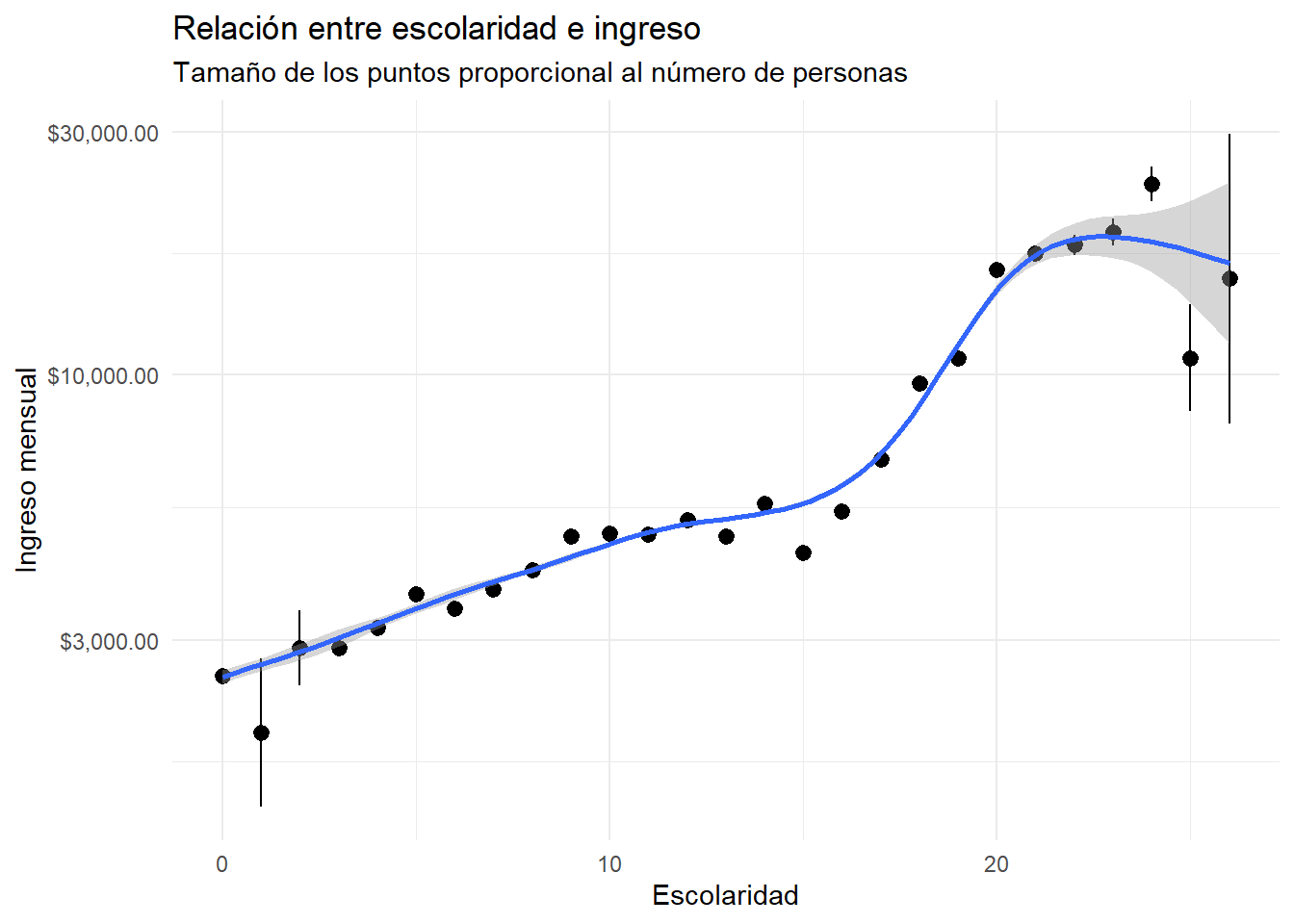
La relación entre escolaridad e ingreso parece ser no lineal: para algunos años de escolaridad, el rendimiento es mayor que para otros: la pendiente de la línea de regresión cambia.
La regresión no paramétrica modela bien esta relación no lineal, pero no nos da la información sobre el rendimiento de la escolaridad que queremos.