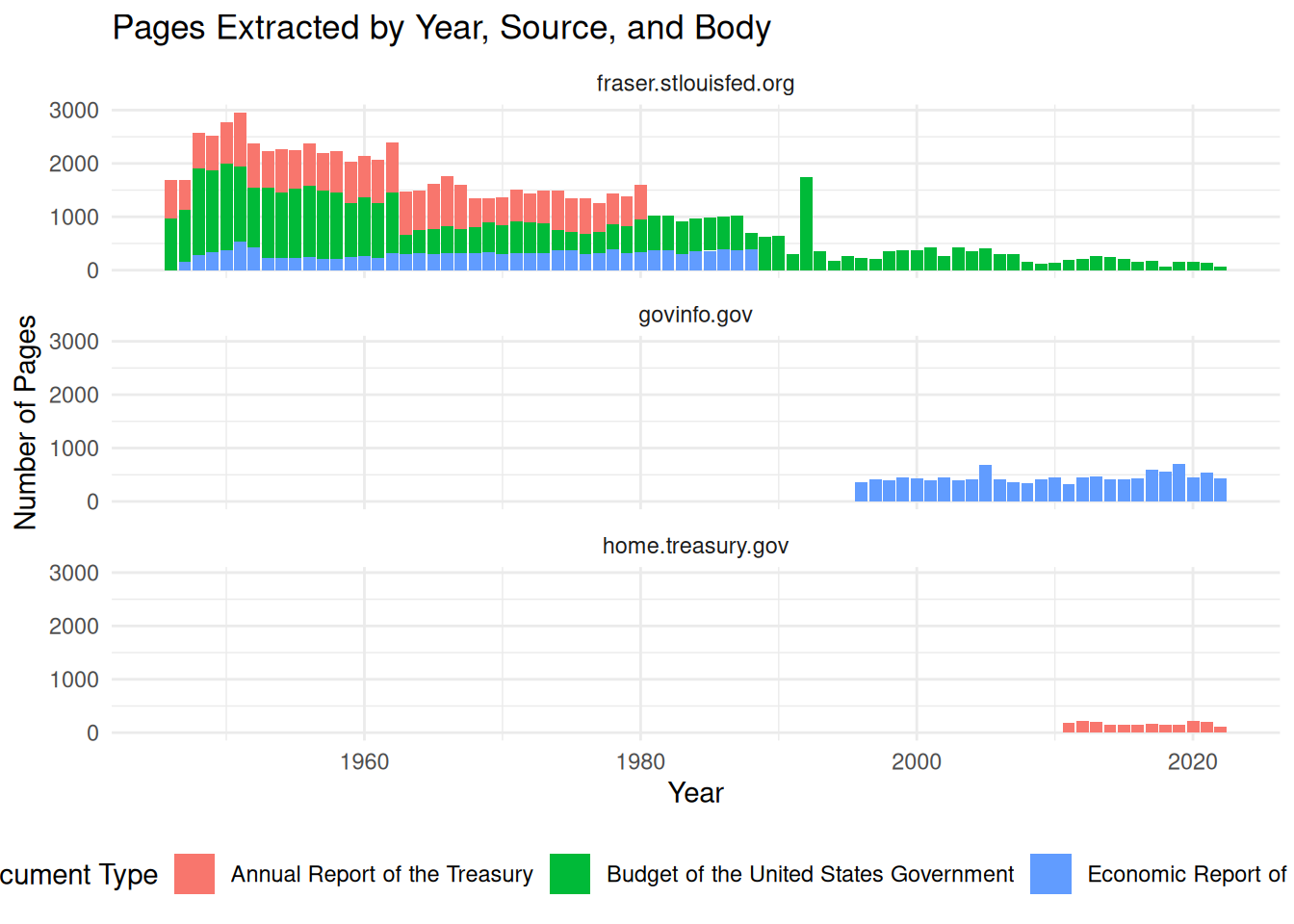
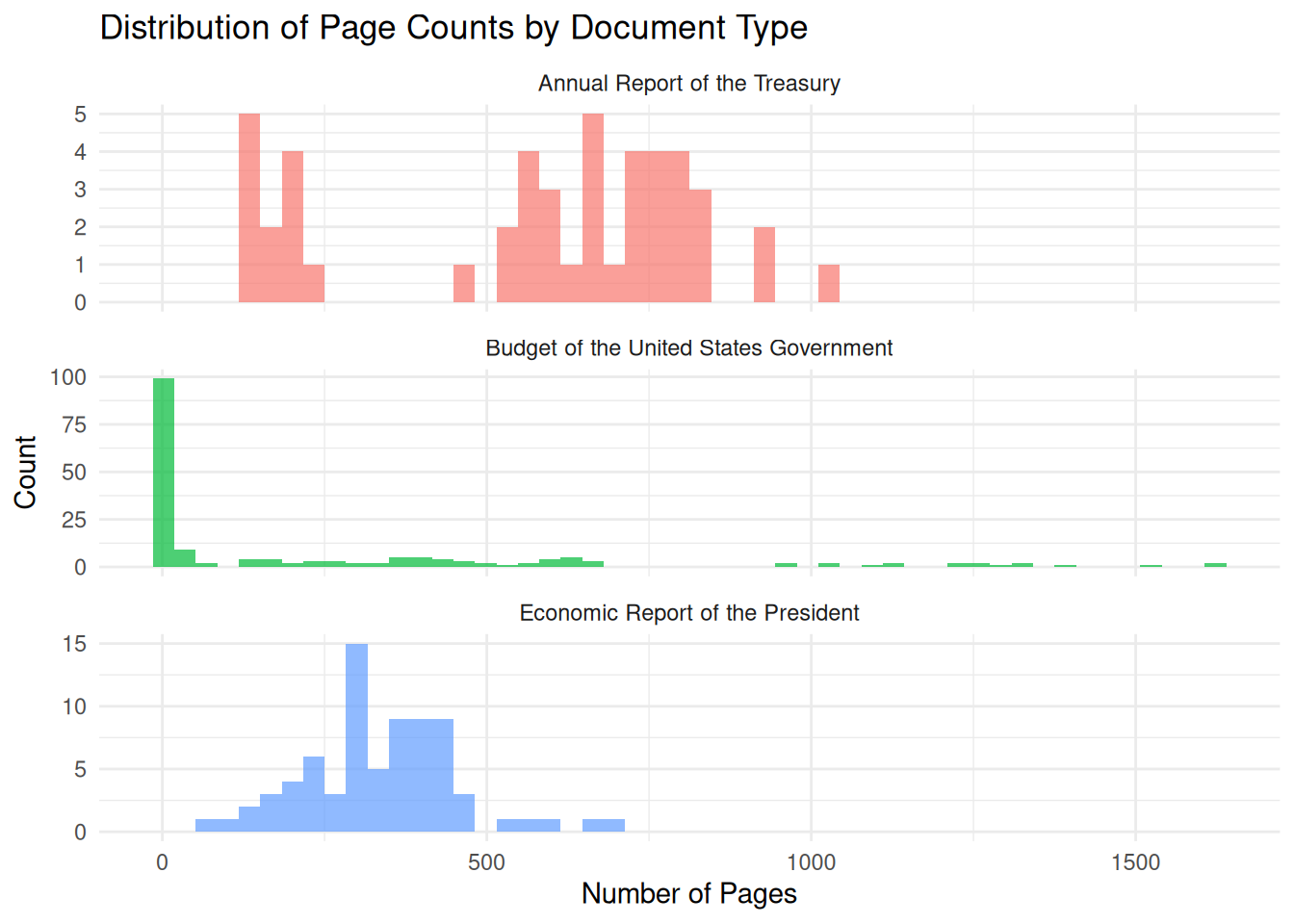
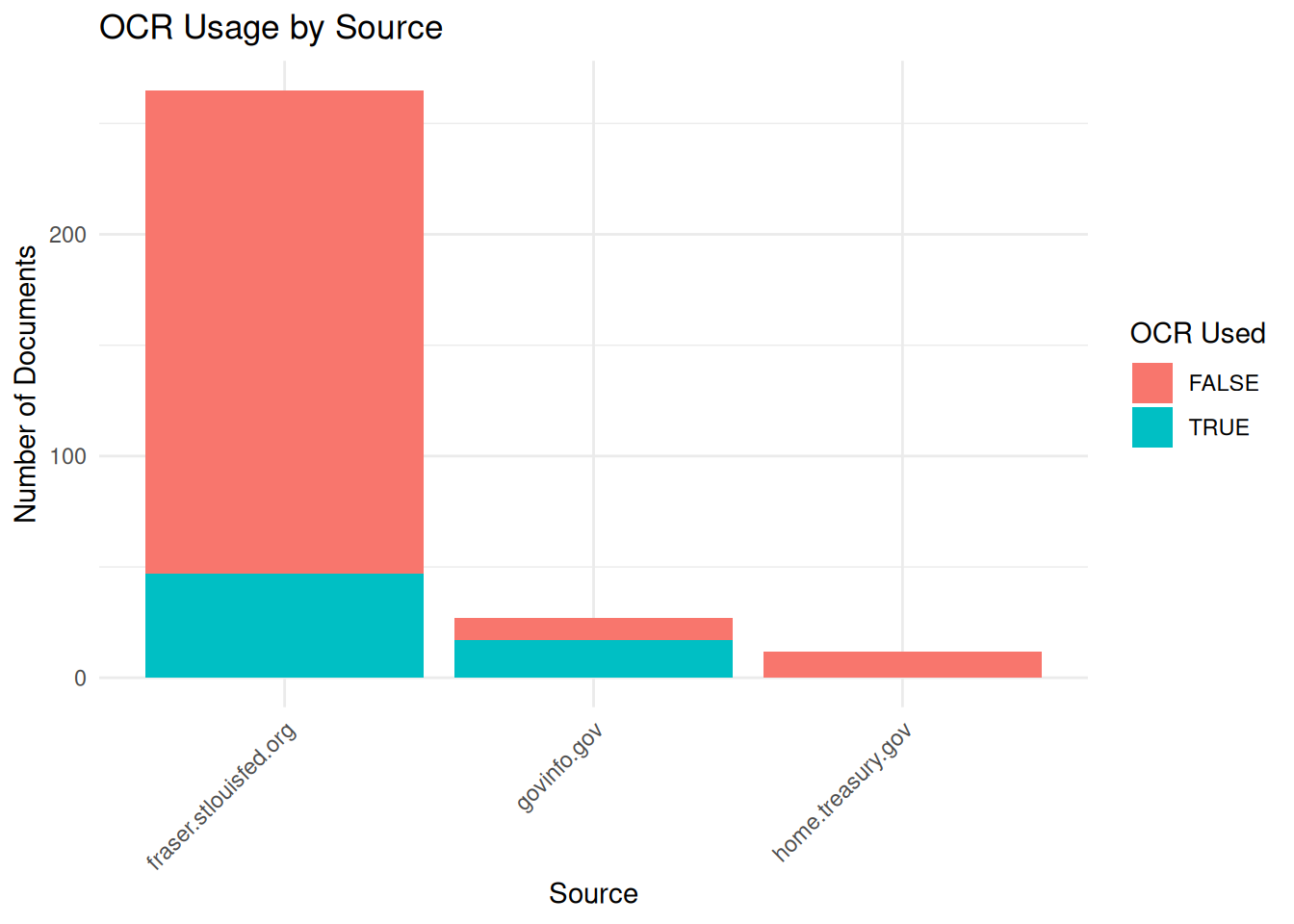
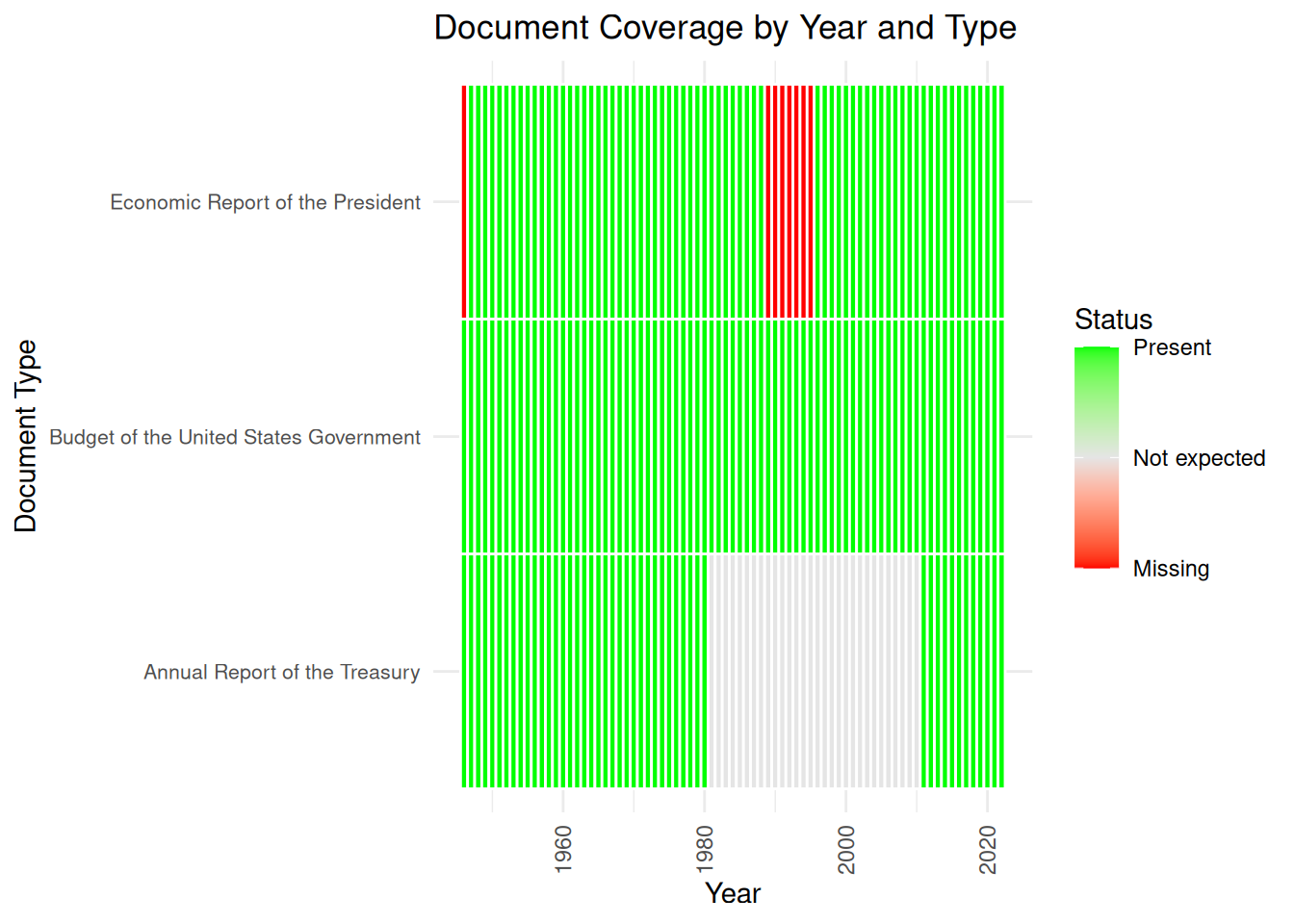
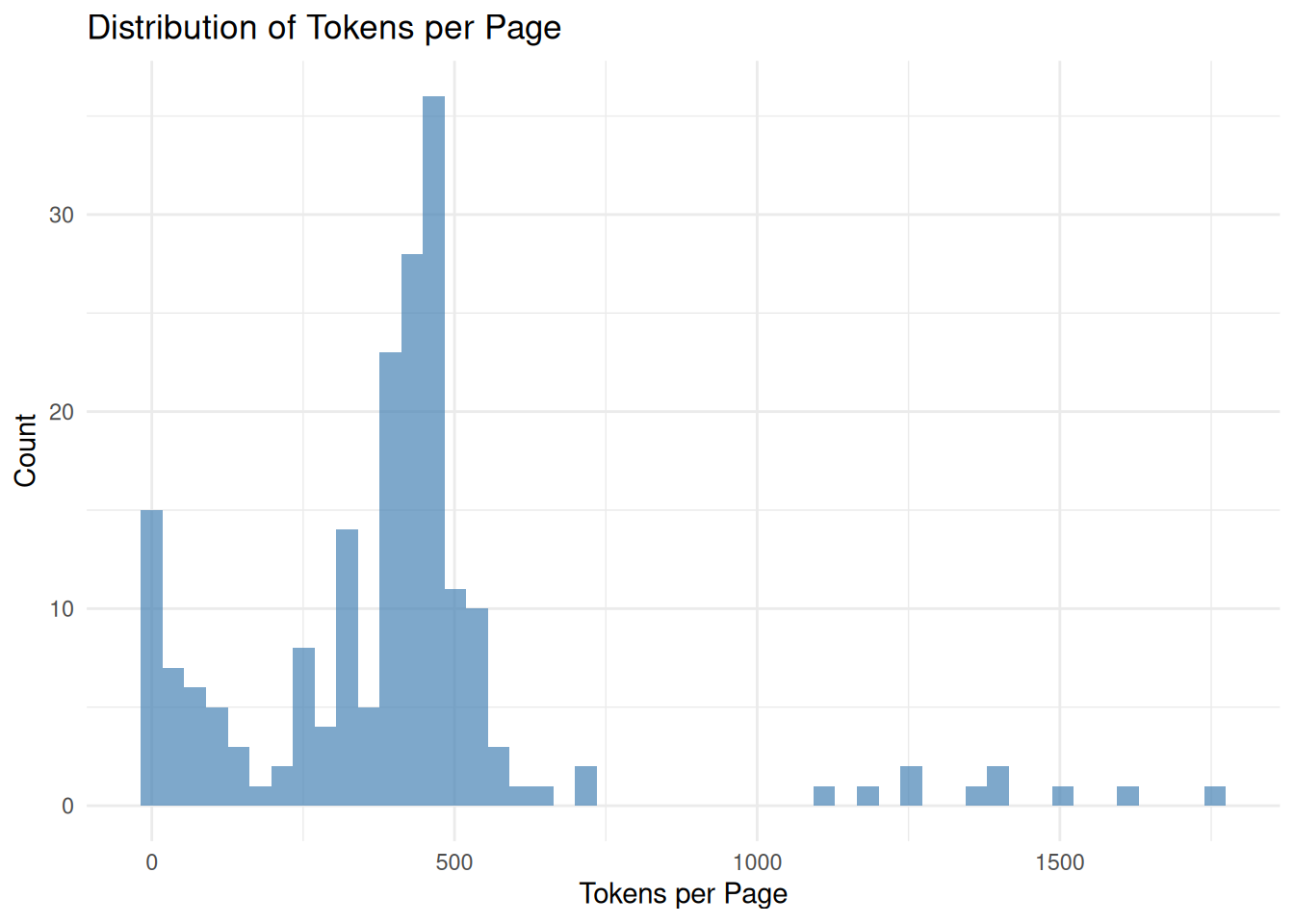
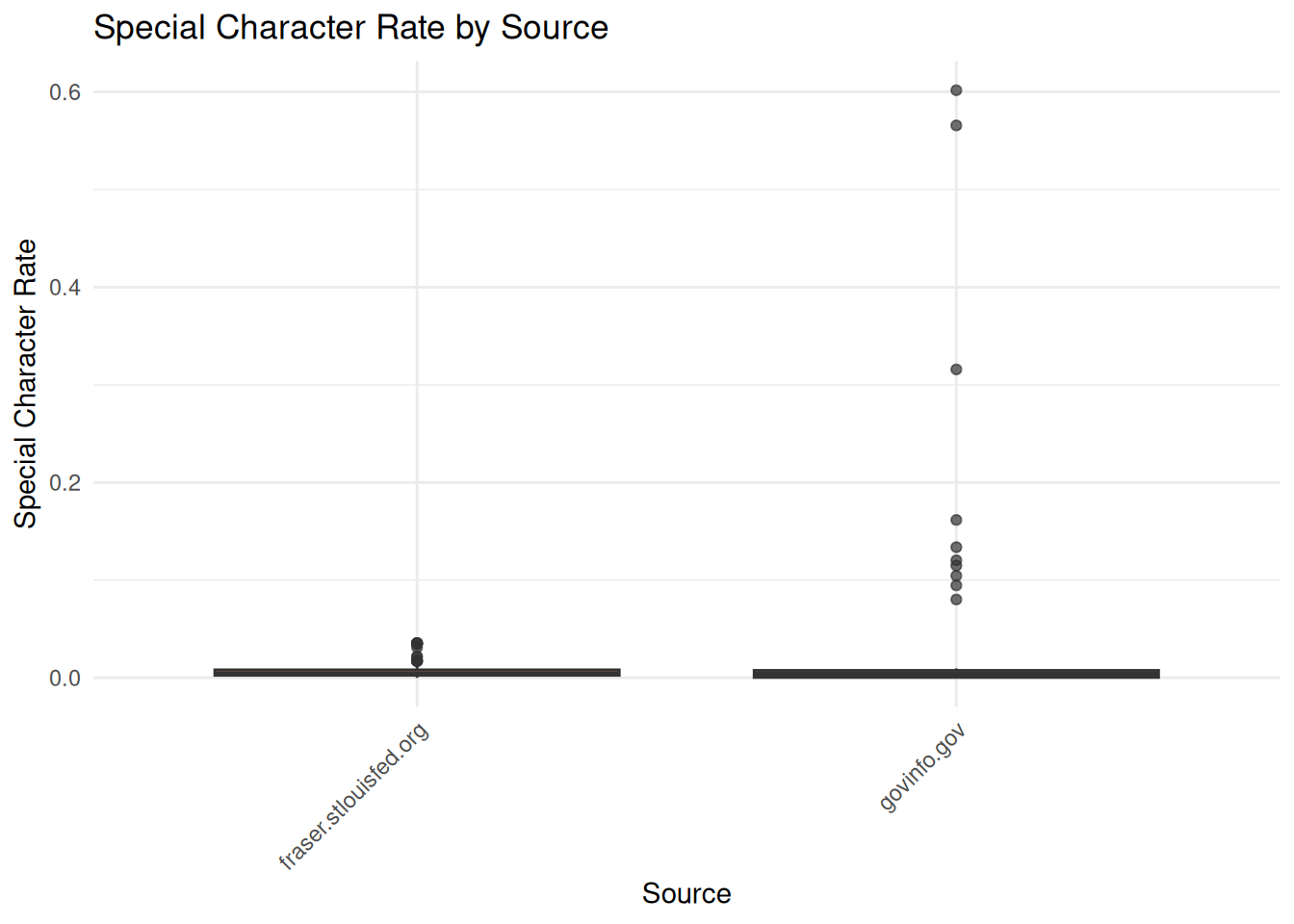
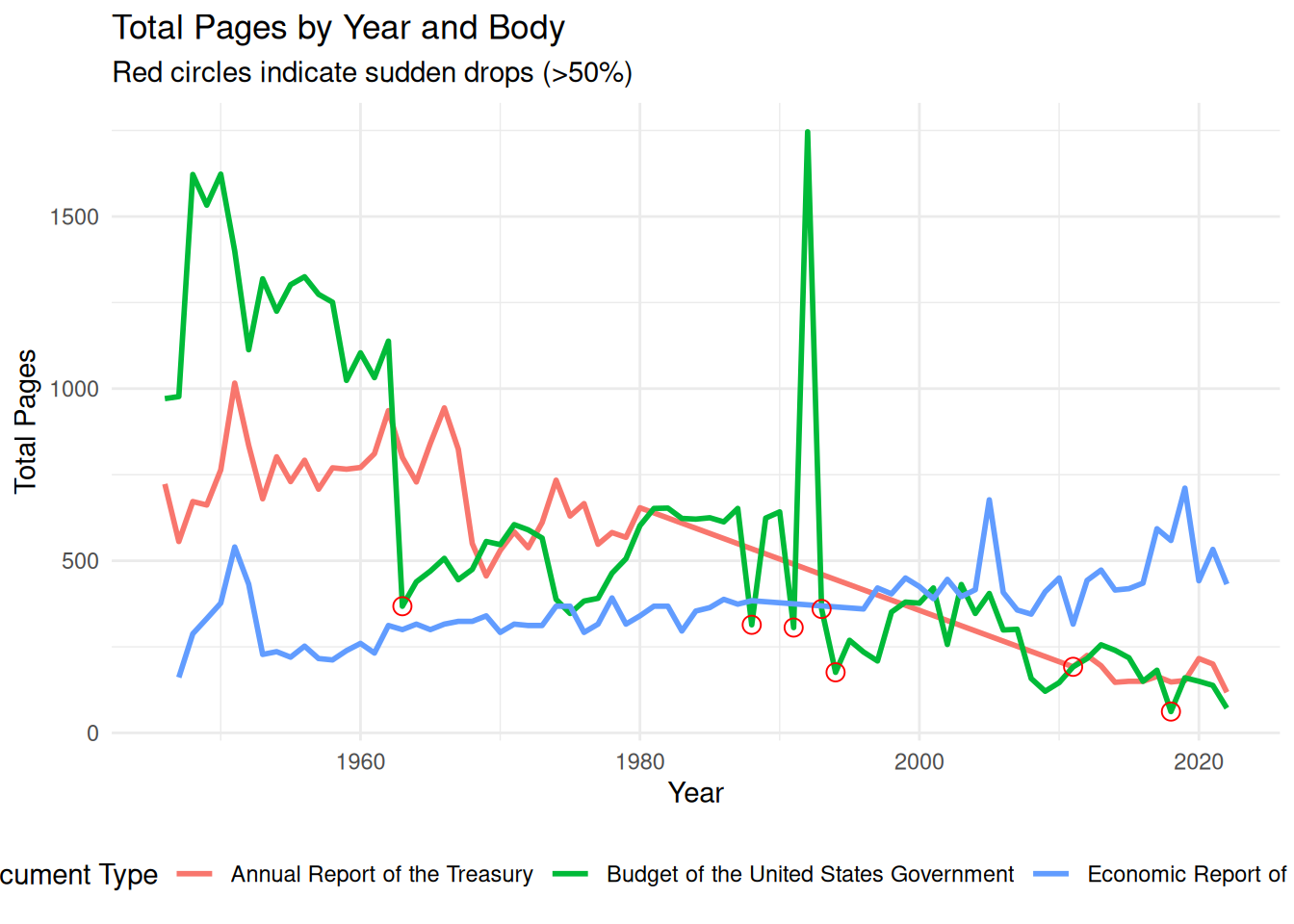
# Calculate page-level quality metrics
# Compile fiscal terms regex once for efficiency
fiscal_regex <- regex(paste(fiscal_terms, collapse = "|"), ignore_case = TRUE)
quality_metrics <- body_data %>%
filter(n_pages > 0) %>%
sample_n(size = min(5, n())) %>% # Reduced sample size for performance
select(year, body, package_id, source, text) %>% # Keep identifiers
mutate(
page_metrics = map(text, function(text_list) {
# Handle the nested structure: text is a list-column
if (is.null(text_list) || length(text_list) == 0) return(NULL)
# Extract pages from the nested list structure
pages <- if (is.list(text_list[[1]])) text_list[[1]] else text_list
if (length(pages) == 0) return(NULL)
# Limit to first 50 pages per document to avoid memory issues
pages <- pages[1:min(50, length(pages))]
tibble(
page_num = seq_along(pages),
page_text = as.character(pages),
n_chars = nchar(page_text),
# Use simple word count instead of quanteda for performance
n_tokens = str_count(page_text, "\\S+"),
special_char_rate = str_count(page_text, "[^a-zA-Z0-9\\s.,!?;:'-]") / pmax(n_chars, 1),
whitespace_rate = str_count(page_text, "\\s") / pmax(n_chars, 1),
non_ascii_rate = str_count(page_text, "[^\x01-\x7F]") / pmax(n_chars, 1),
has_fiscal_terms = str_detect(page_text, fiscal_regex)
)
})
) %>%
filter(!map_lgl(page_metrics, is.null)) %>%
select(-text) %>% # Remove text column before unnest
unnest(page_metrics)
# Identify suspicious pages
suspicious_pages <- quality_metrics %>%
filter(
n_chars < 100 |
special_char_rate > 0.1 |
non_ascii_rate > 0.05 |
(!has_fiscal_terms & page_num > 5)
)
# Document-level quality summary
doc_quality <- quality_metrics %>%
group_by(year, body, package_id) %>%
summarize(
total_pages = n(),
avg_tokens_per_page = mean(n_tokens, na.rm = TRUE),
pct_fiscal_pages = mean(has_fiscal_terms, na.rm = TRUE),
suspicious_pages_count = sum(
n_chars < 100 | special_char_rate > 0.1 | non_ascii_rate > 0.05,
na.rm = TRUE
),
quality_score = (pmin(avg_tokens_per_page / 300, 1)) * pct_fiscal_pages *
(1 - suspicious_pages_count / total_pages),
.groups = "drop"
)
# Calculate metrics
pct_suspicious <- nrow(suspicious_pages) / nrow(quality_metrics)
pct_fiscal <- mean(quality_metrics$has_fiscal_terms, na.rm = TRUE)
test_v_status <- case_when(
pct_suspicious < 0.05 & pct_fiscal > 0.70 ~ "PASS",
pct_suspicious < 0.10 | pct_fiscal > 0.50 ~ "WARN",
TRUE ~ "FAIL"
)
test_results$test_v_quality <- list(
metric = "Text quality - suspicious pages",
value = sprintf("%.1f%%", pct_suspicious * 100),
target = "<5%",
status = test_v_status
)
test_results$test_v_fiscal <- list(
metric = "Text quality - fiscal pages",
value = sprintf("%.1f%%", pct_fiscal * 100),
target = ">70%",
status = test_v_status
)