Predicción, clasificación y pronóstico
Clase 4
2 de abril de 2025
Relación lineal de las variables con incumplimiento
Respondamos la primera pregunta: cómo afecta cada una de las variables a la probabilidad de incumplimiento.
Para esto, ajustamos un modelo de probabilidad lineal por cada una de las variables independientes:
pacman::p_load(fixest)
Default <- Default |>
mutate(
default = as.numeric(default == "Yes"),
student = as.numeric(student == "Yes")
)
Default |>
feols(
default ~ sw(balance, income, student)
) |>
etable(
title = "Modelo de probabilidad lineal",
fitstat = ~ n + r2 + my + f,
markdown = T,
digits = 3
)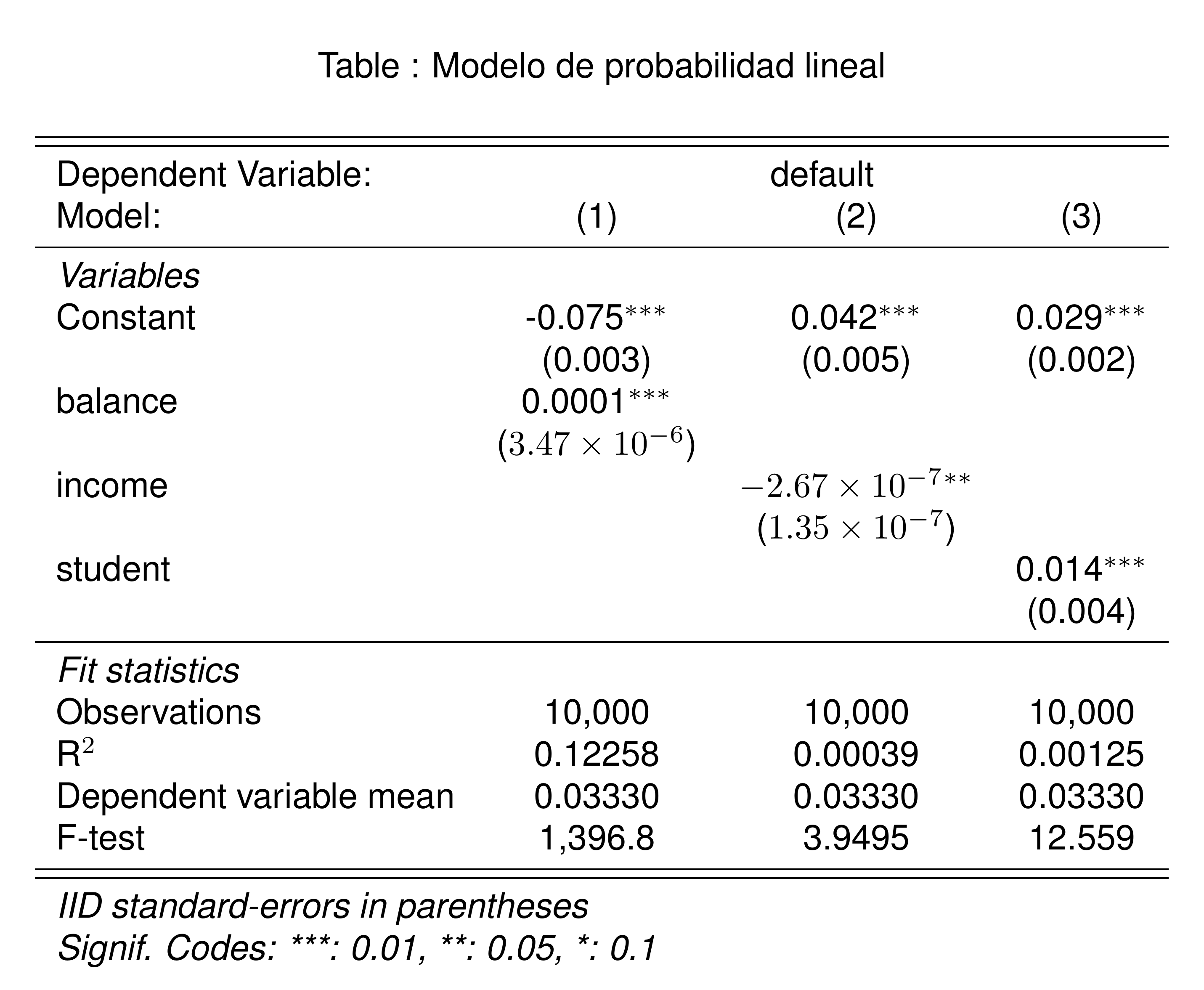
Pregunta: ¿Cómo interpretamos los resultados?
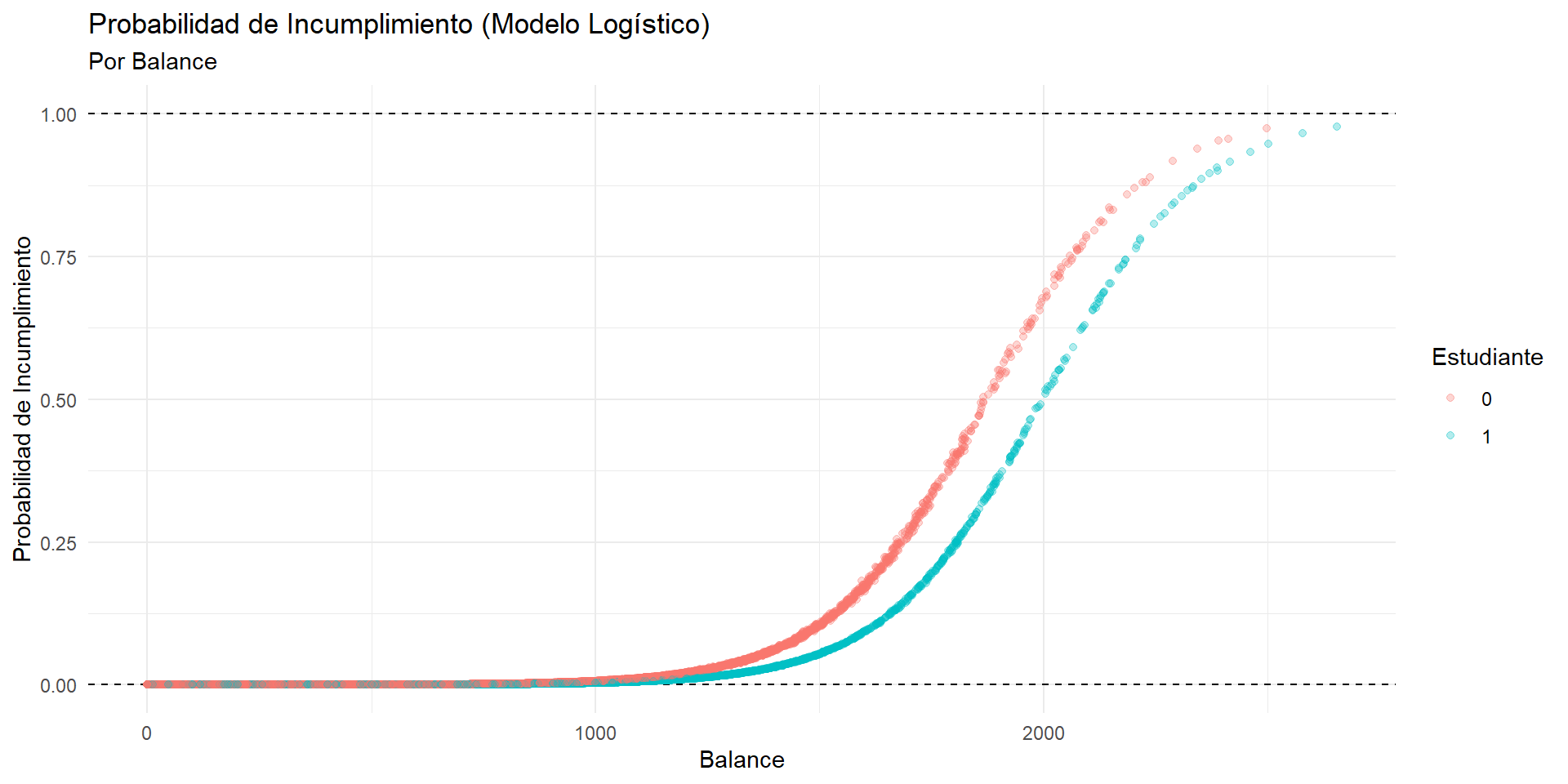
Visualización de la predicción
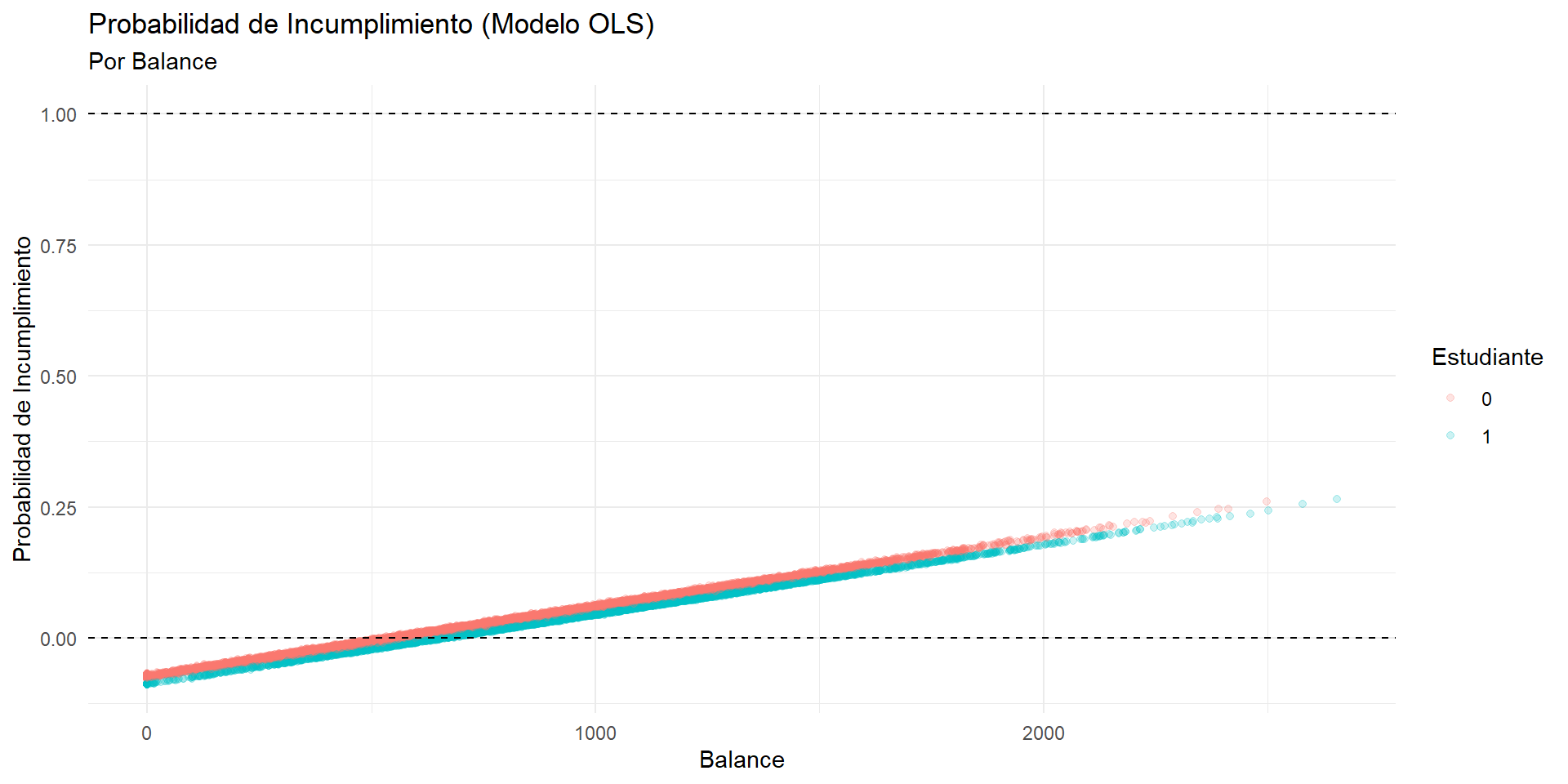
Visualización de la predicción
Simulación
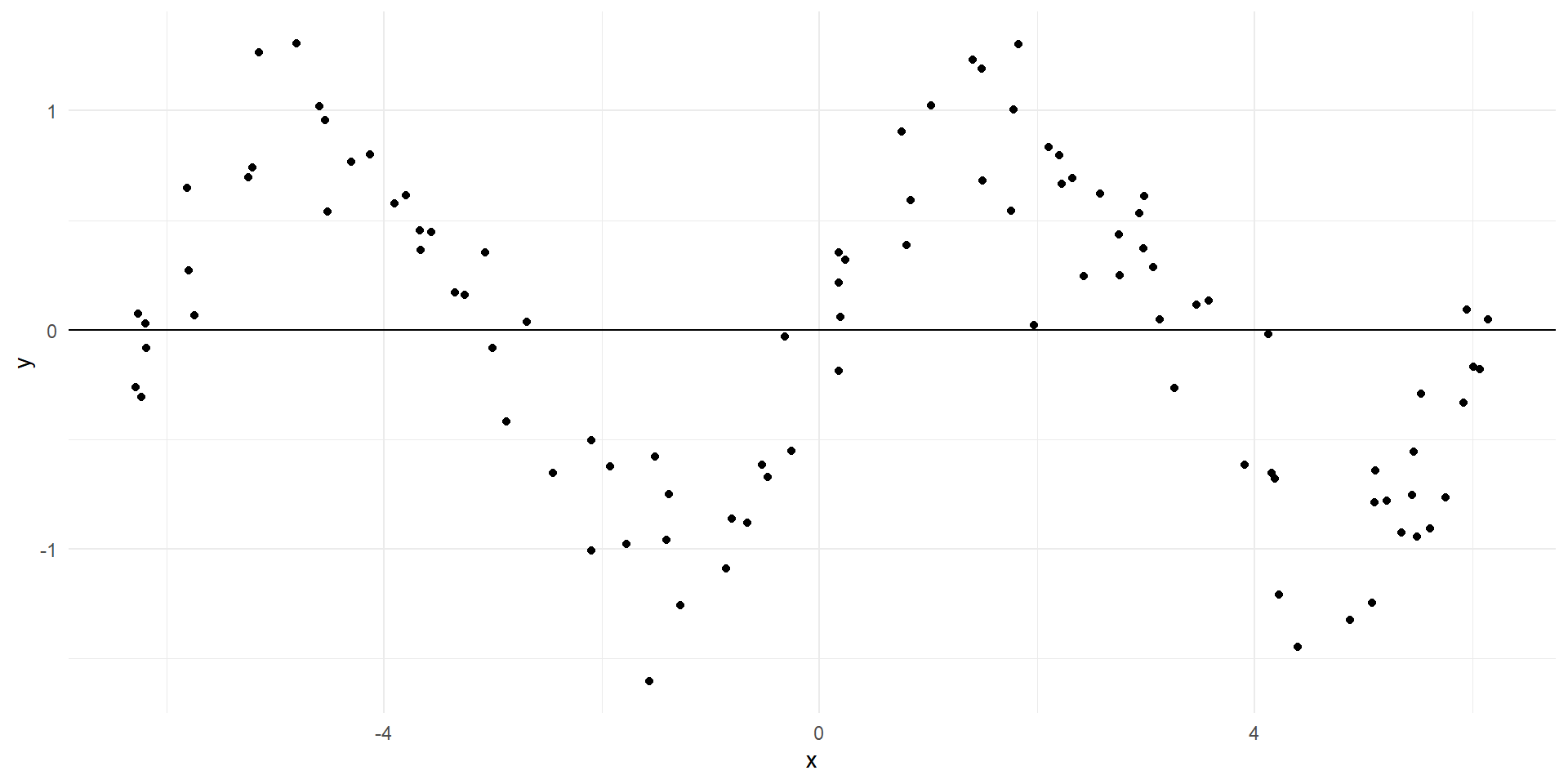
Ajuste de un modelo lineal
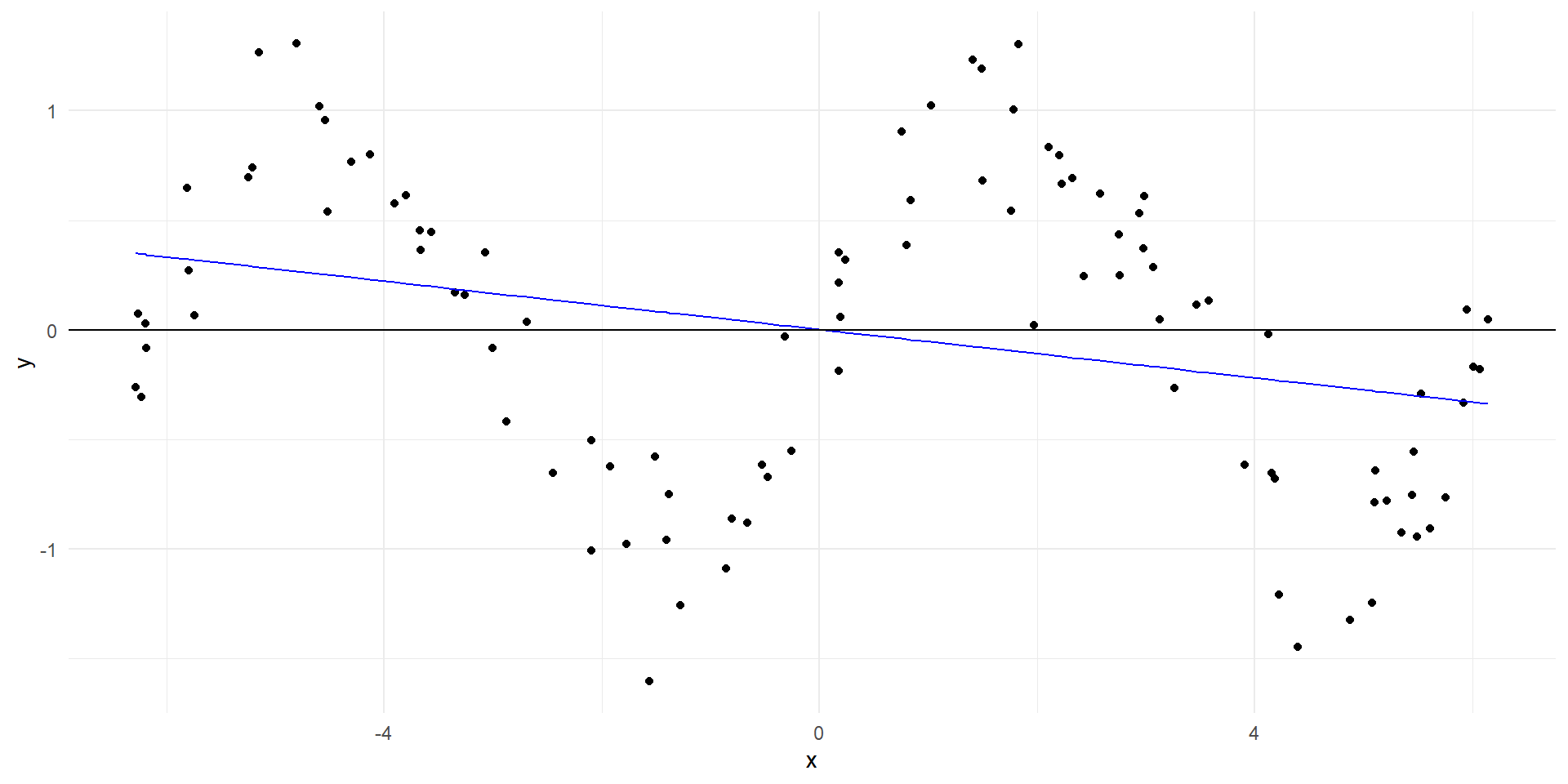
Ajuste polinomial
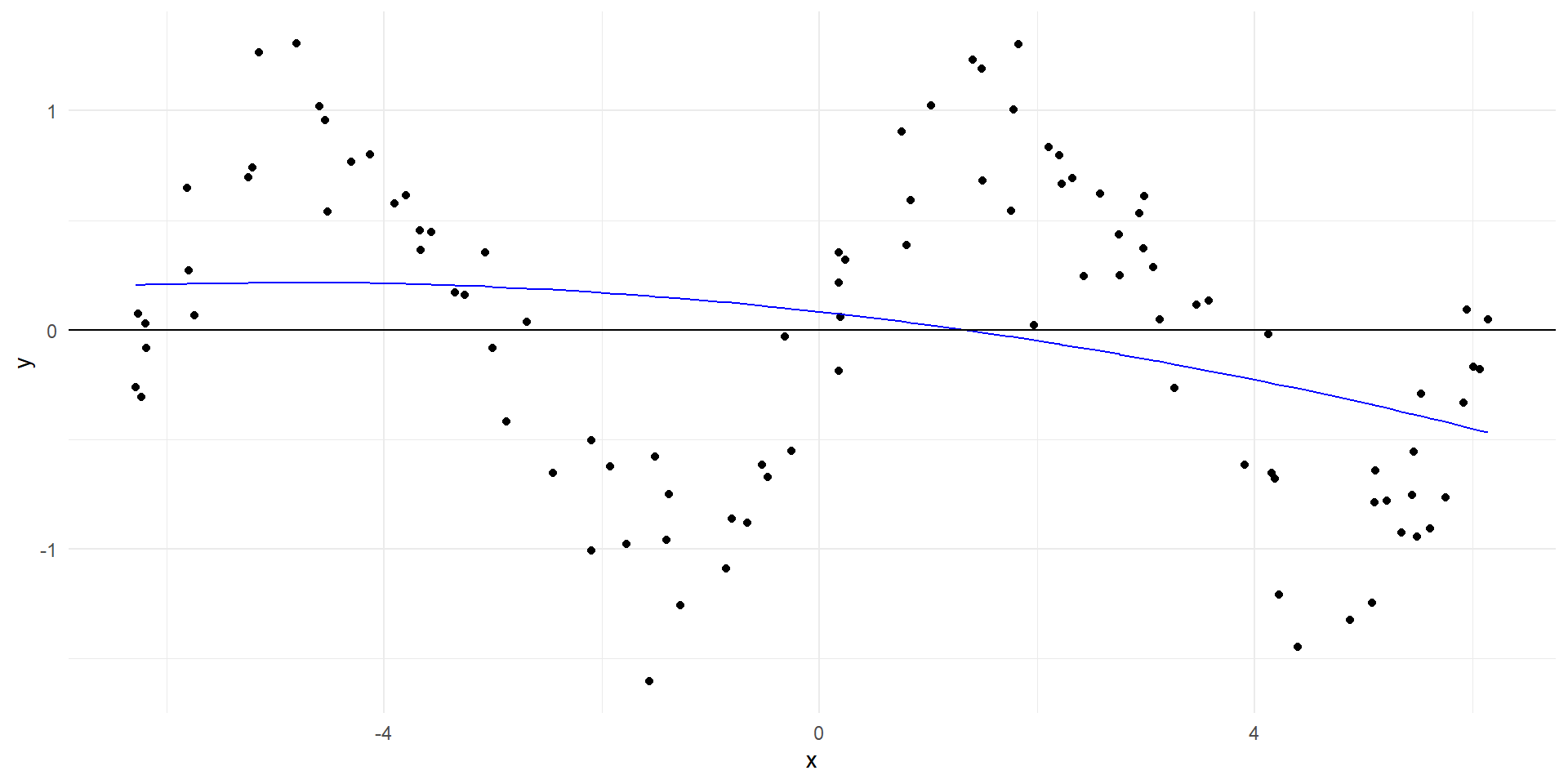
Ajuste polinomial de mayor orden
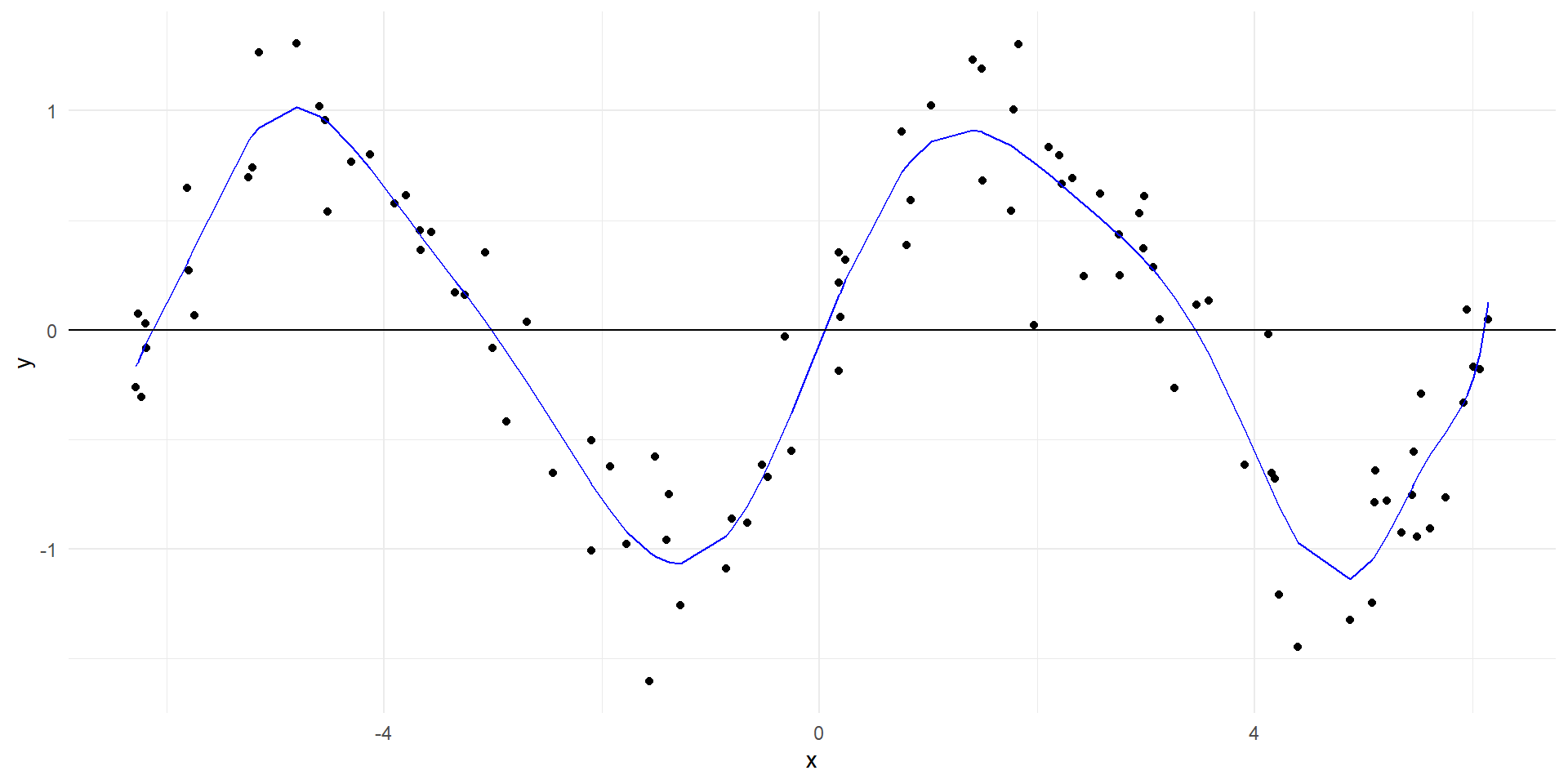
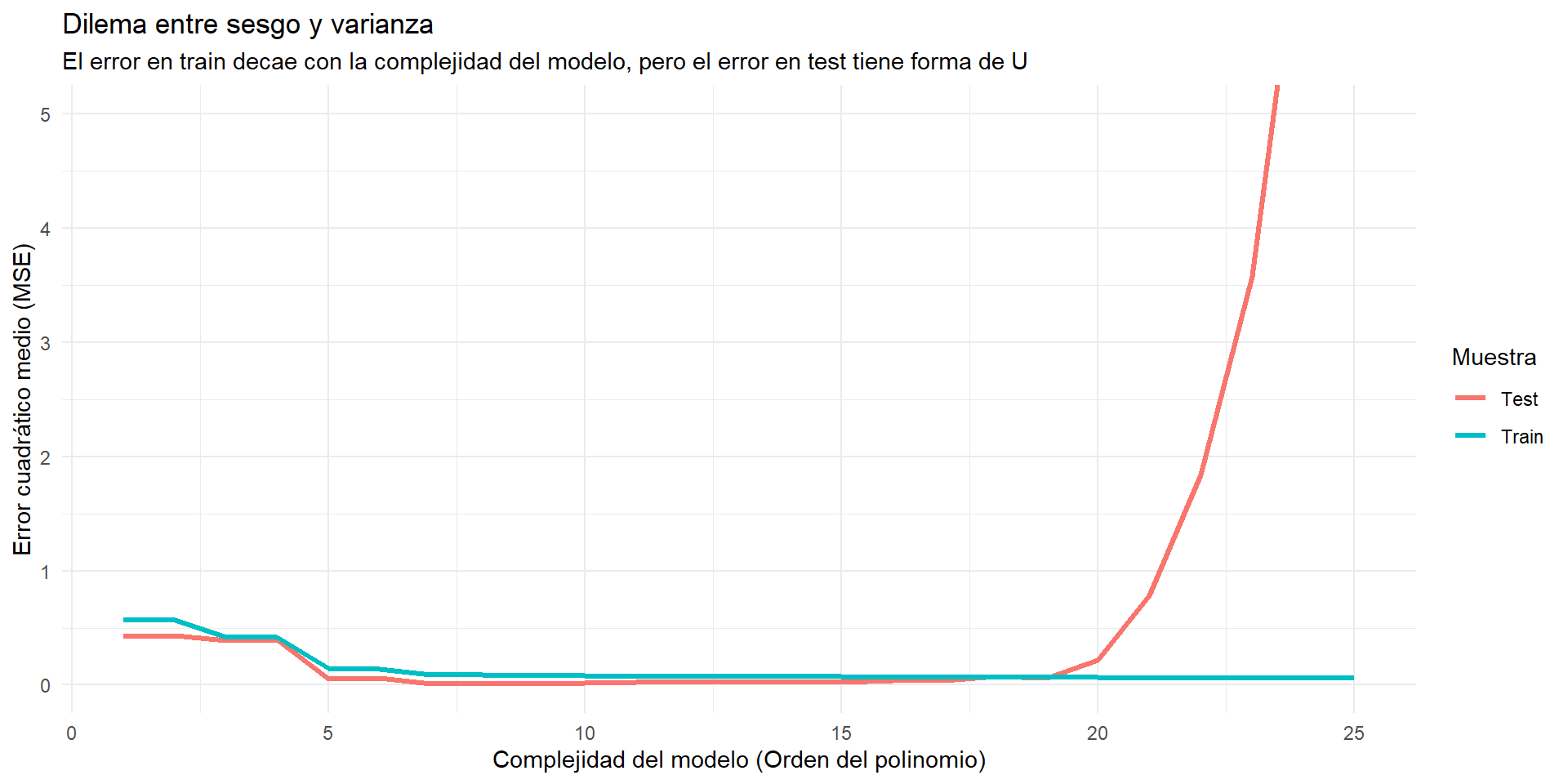
Evaluación de los modelos
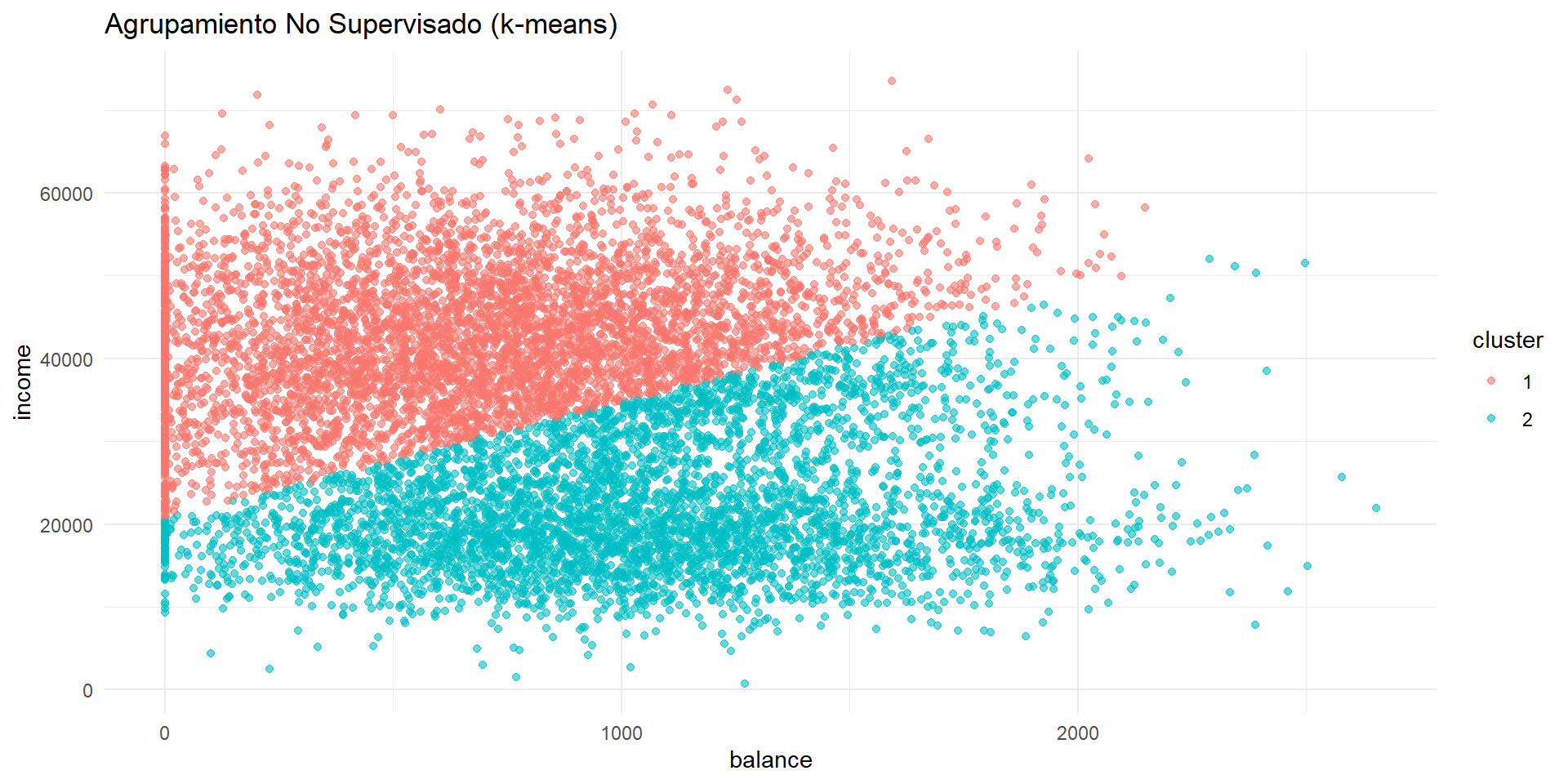
Agrupamiento por k-means
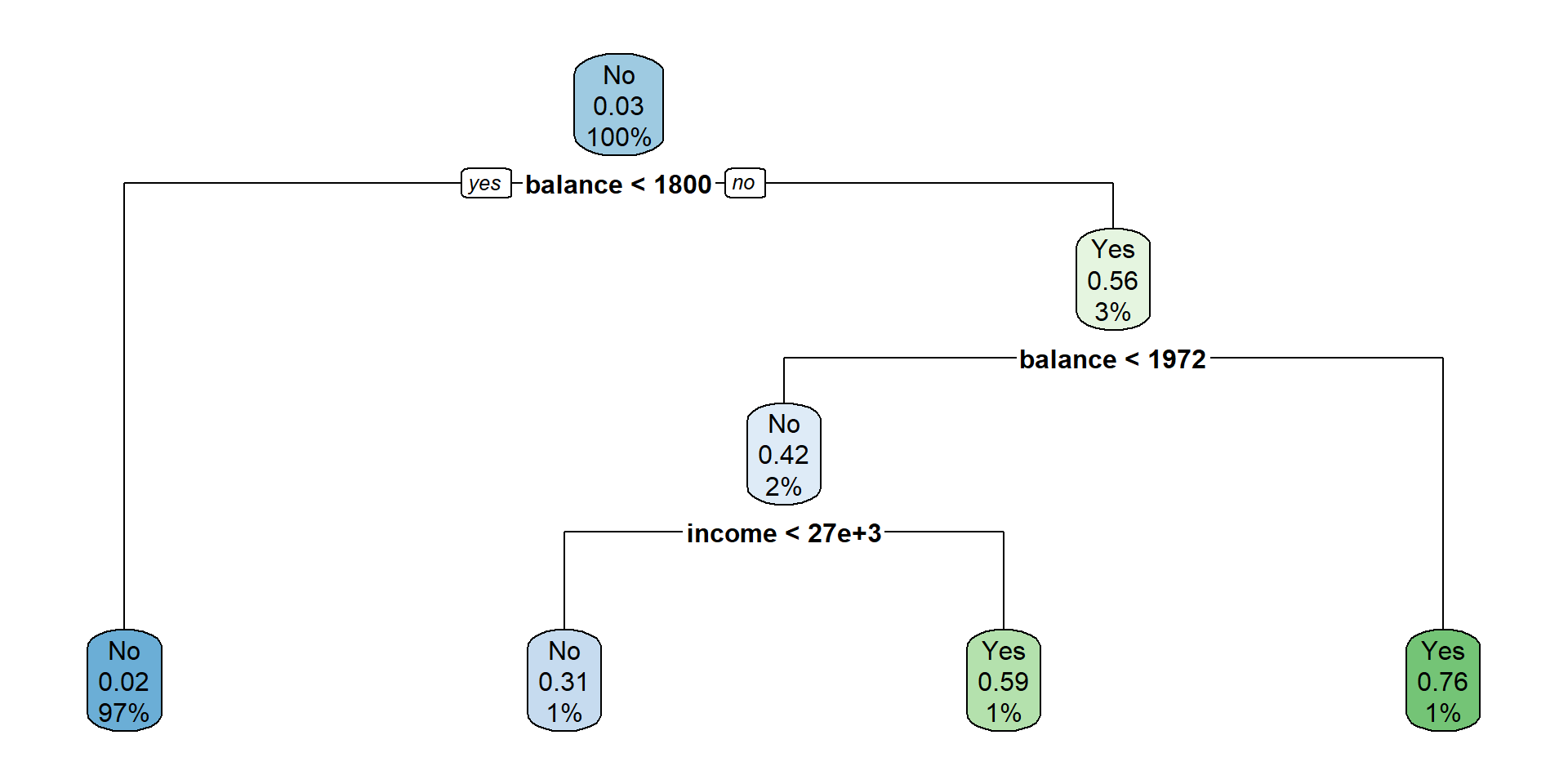
Un árbol
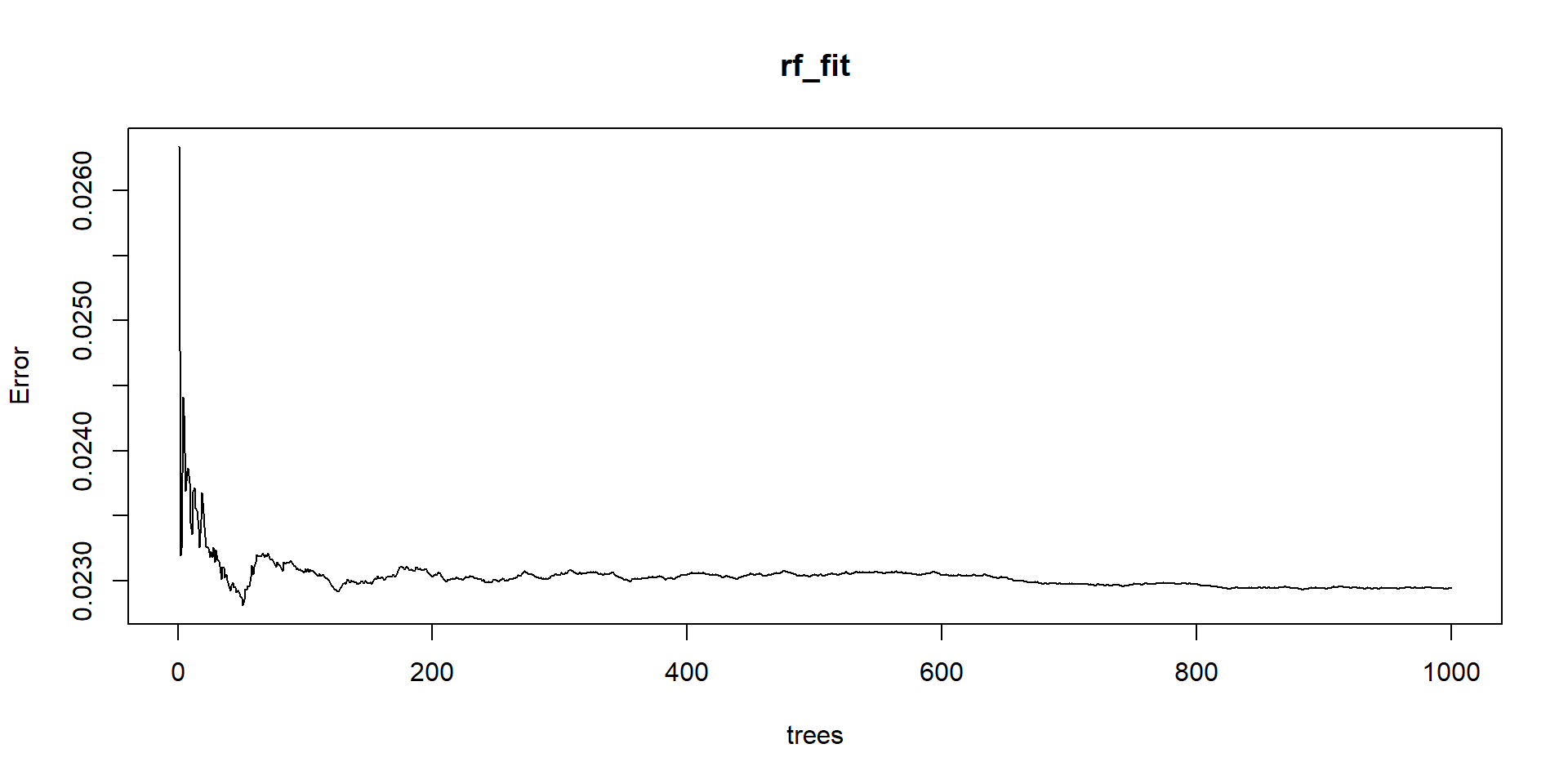
Error irreducible
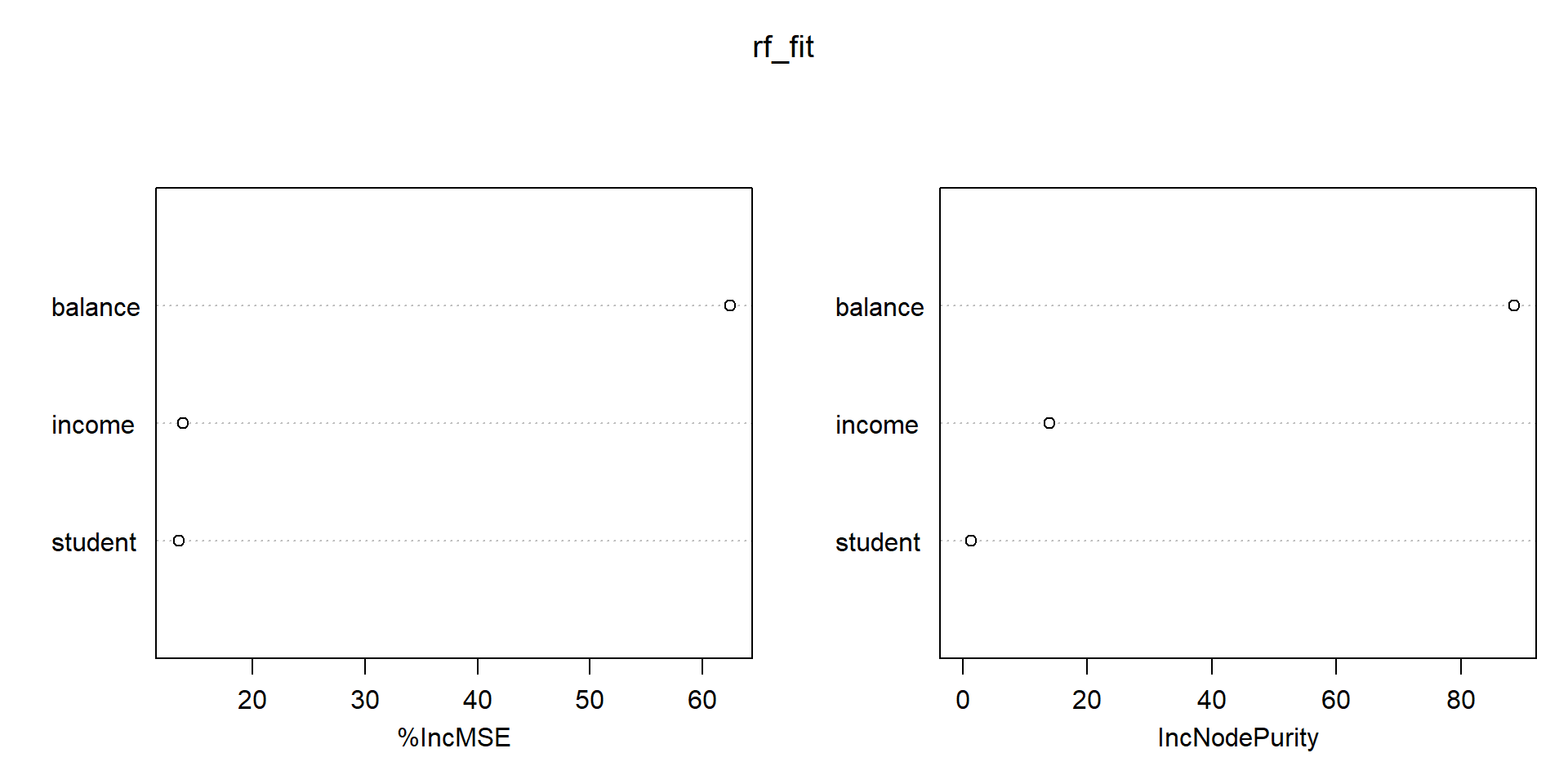
Importancia de las variables
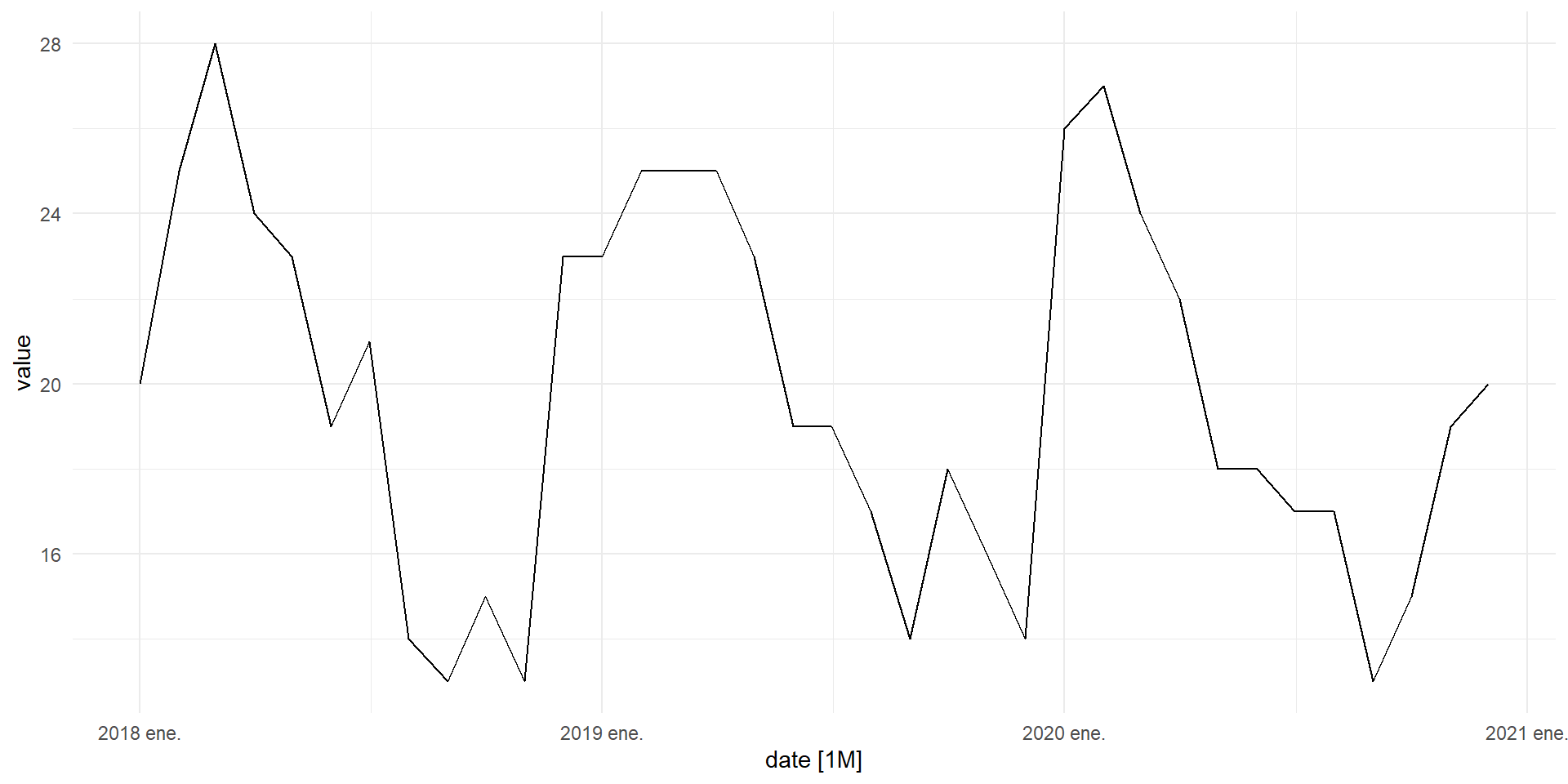
Datos
Simularemos datos del número de incumplimientos de deuda en el tiempo.
Pronósticos